PINNの基礎理論 — トラブルシューティングガイド
より充実した内容を pinn-fundamentals.html でご覧いただけます。
トラブルシューティング
PINNの基礎理論でよくある問題と対処法をまとめる。
1. モデルの過学習
「モデルの過学習」について教えてください!
症状: 訓練誤差は小さいが検証誤差が大きい。訓練データへの過度な適合が発生。
対処: 正則化(L2, Dropout)の追加、データ拡張、交差検証によるハイパーパラメータ調整。早期停止(Early Stopping)の導入。
先生の説明分かりやすい! の基礎理論でよくあるのモヤモヤが晴れました。
2. 予測精度の不足
次は予測精度の不足の話ですね。どんな内容ですか?
症状: 検証データでの精度がR²<0.9に留まり実用的な予測が困難。
対処: 特徴量エンジニアリングの見直し、サンプル数の増加、モデル複雑度の段階的向上、アンサンブル手法の適用。
3. 学習の不安定性
「学習の不安定性」について教えてください!
症状: 損失関数が振動・発散し収束しない。
対処: 学習率の低減またはスケジューラ導入、バッチ正規化の追加、勾配クリッピングの適用。
4. 計算リソース不足
「計算リソース不足」について教えてください!
症状: GPUメモリ不足(OOM)エラーや学習時間の超過。
対処: バッチサイズ削減、混合精度学習(FP16)、モデル並列化、勾配チェックポインティングの導入。
5. データ関連の問題
「データ関連の問題」について教えてください!
症状: 学習データの不足、偏り、ノイズによりモデル性能が低下する。
対処: データ拡張(物理的な対称性の活用)、能動学習による効率的なデータ収集、ロバスト学習手法の適用。外れ値検出と除去のパイプラインを構築する。
なるほど。じゃあの基礎理論でよくあるができていれば、まずは大丈夫ってことですか?
1. 学習が収束しない
学習が収束しないって、具体的にはどういうことですか?
症状: 損失関数が振動し続ける、またはNaN/Infになる
考えられる原因:
- 学習率が高すぎる
- データの正規化が不適切
- ネットワークが深すぎる(勾配消失/爆発)
対策:
- 学習率を1/10に下げて再試行
- 入力・出力の標準化を確認(平均0、分散1)
- 勾配クリッピングの導入:
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) - バッチ正規化/層正規化の追加
つまりの基礎理論でよくあるのところで手を抜くと、後で痛い目を見るってことですね。肝に銘じます!
2. 過学習(訓練誤差は低いが検証誤差が高い)
「過学習」について教えてください!
症状: 訓練データに対する予測は良好だが、未知データでの精度が低い
対策:
- ドロップアウト層の追加(率: 0.1-0.5)
- 訓練データの増量(追加シミュレーション、データ拡張)
- モデルの複雑さを低減(層数・ニューロン数の削減)
- 早期停止(Early Stopping)の厳格化
3. 物理的に非現実的な予測
物理的に非現実的な予測って、具体的にはどういうことですか?
症状: 負の濃度、エネルギー非保存などの非物理的な出力
対策:
- 物理制約を損失関数に追加(PINN的アプローチ)
- 出力層に活性化関数を追加(ReLUで非負制約等)
- 後処理で物理的な補正を適用
先生の説明分かりやすい! の基礎理論でよくあるのモヤモヤが晴れました。
体系的なデバッグ手順
先生もPINNの基礎理論で徹夜デバッグしたことありますか?(笑)
ステップ1: 問題の切り分け
ステップって、具体的にはどういうことですか?
1. エラーメッセージの完全な記録(ログファイルの保存)
2. 最小再現ケースの作成(形状・条件を単純化)
3. 既知のベンチマーク問題での動作確認
4. 前バージョンでの動作確認(ソフトウェアのバグの可能性)
ステップ2: 入力データの検証
「ステップ」について教えてください!
先生の説明分かりやすい! ステップのモヤモヤが晴れました。
ステップ3: 段階的な複雑化
「ステップ」について教えてください!
1. 最小構成(単一要素、単純形状)で解が得られることを確認
2. 荷重/境界条件を段階的に追加
3. 非線形性を段階的に導入
4. 問題が発生する条件を特定
ステップ4: 結果の妥当性確認
次はステップの話ですね。どんな内容ですか?
よくある質問(FAQ)
「よくある質問(FAQ)」って聞いたことはあるんですけど、ちゃんと理解できてないかもしれません…
Q: 計算が終わらない場合は?
次は計算が終わらない場合はの話ですね。どんな内容ですか?
A: まずメモリ使用量を確認。メモリ不足の場合はアウトオブコア解法に切替。CPU負荷が低い場合はI/Oボトルネックの可能性。
Q: 異なるソルバーで結果が異なる場合は?
異なるソルバーで結果が異なる場って、具体的にはどういうことですか?
A: 要素タイプ、積分スキーム、収束判定基準の差異を確認。同一条件での比較にはメッシュ変換の影響にも注意。
おお〜、計算が終わらない場合の話、めちゃくちゃ面白いです! もっと聞かせてください。
Q: メッシュ依存性がなくならない場合は?
次はメッシュ依存性がなくならない場の話ですね。どんな内容ですか?
A: 応力特異点(ノッチ、角部)の存在を確認。特異点近傍ではメッシュ細分化しても値は収束しない→サブモデリングや応力線形化を適用。
エラーログの読み方
先生もPINNの基礎理論で徹夜デバッグしたことありますか?(笑)
ログレベルの分類
ログレベルの分類って、具体的にはどういうことですか?
| レベル | 意味 | 対応 |
|---|---|---|
| INFO | 情報メッセージ | 通常は無視可 |
| WARNING | 警告(計算は継続) | 原因を確認、必要なら対処 |
| ERROR | エラー(計算は継続可能な場合あり) | 原因を特定し修正 |
| FATAL | 致命的エラー(計算中断) | 必ず修正が必要 |
系統的なトラブルシューティング手法
「系統的なトラブルシューティング」について教えてください!
5W1H分析: いつ(When)、どこで(Where)、何が(What)、なぜ(Why)、誰が(Who)、どうやって(How)エラーが発生したかを整理する。
二分探索法: 正常に動作する最小ケースから出発し、条件を段階的に追加して問題箇所を特定する。各ステップで1つの変更のみ行い、原因を切り分ける。
なるほど…ログレベルの分類って一見シンプルだけど、実はすごく奥が深いんですね。
サポートへの問い合わせ時の準備
サポートへの問い合わせ時の準備って、具体的にはどういうことですか?
いやぁ、PINNの基礎理論って奥が深いですね… でも先生の説明のおかげでだいぶ整理できました!
うん、いい調子だよ! 実際に手を動かしてみることが一番の勉強だからね。分からないことがあったらいつでも聞いてくれ。
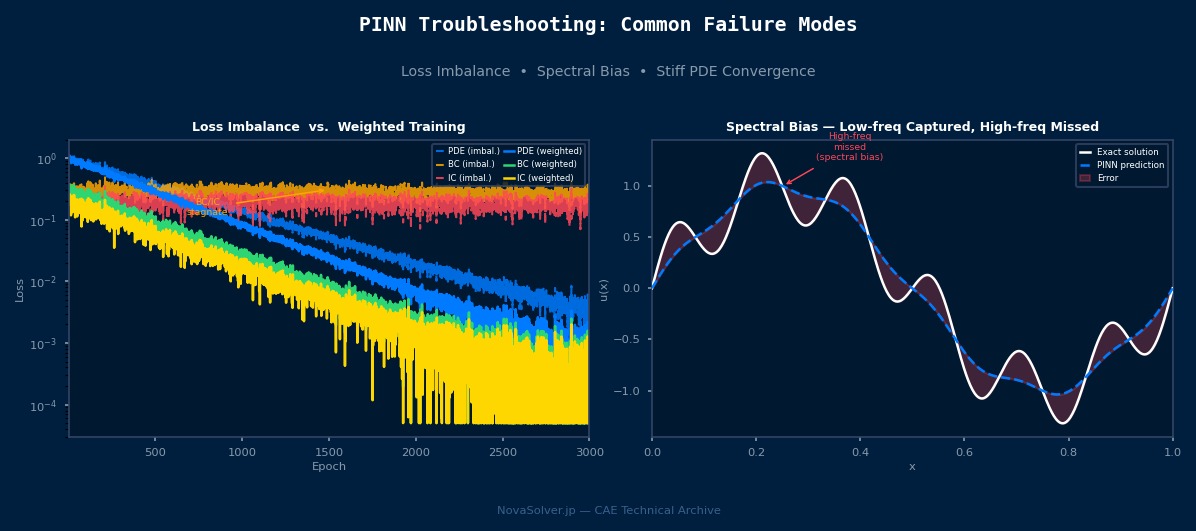
PINN「謎の発散」を追え——デバッグの第一手は損失の分解
PINNのデバッグで「全体損失は下がっているのに解が変」というケースが意外と多い。その原因はほぼ決まっていて、境界条件損失だけが下がってPDE損失が無視されている状態だ。対策は損失を分解してTensorBoardで可視化すること。PDE残差・境界条件・初期条件の3つを別々にプロットすると、どこでバランスが崩れているかが一目瞭然になる。「全体損失しか見ていない」のがPINNデバッグ初心者の典型的なミスだ。
AI×CAEはまだ発展途上の分野です。 — Project NovaSolverは、機械学習と従来型ソルバーの融合がもたらす可能性を探求しています。
CAEの未来を、実務者と共に考える
Project NovaSolverは、PINNの基礎理論における実務課題の本質に向き合い、エンジニアリングの現場を支える道具づくりを目指す研究開発プロジェクトです。
プロジェクトの最新情報を見る →関連トピック
なった
詳しく
報告