AutoML与超参数优化
理论与物理
概述
老师!今天要讲AutoML和超参数优化对吧?具体是什么内容呢?
这是用于自动探索CAE所用机器学习模型超参数(学习率、层数、核参数等)的方法。会用到Tree-structured Parzen Estimator(TPE)或BOHB等算法。
哦~,模型超参数的话题,太有意思了!请再多讲一些。
支配方程
用数学公式表示的话是这样的。
嗯…只看公式还是不太明白…这表示的是什么意思呢?
TPE的获取函数:
理论基盘
“理论基盘”这个词我倒是听说过,但可能并没有真正理解…
AutoML和超参数优化是旨在实现数据驱动方法与基于物理建模相融合的重要技术。传统CAE分析中计算成本是主要瓶颈,而引入AutoML和超参数优化可以大幅改善计算效率与预测精度之间的权衡。本方法的数学基础立足于函数逼近理论和统计学习理论,其泛化性能的保证和收敛性的严格解析是理论研究的课题。特别是在输入维度高的情况下,应对“维度灾难”是实用化的关键,降维和稀疏性的利用是重要的方法。
也就是说,如果在超参数这里偷懒,后面会吃苦头对吧。我铭记在心!
数学定式化的细节
接下来是“数学定式化的细节”!这是什么内容呢?
展示将机器学习模型应用于CAE时的基本数学框架。
损失函数的构成
损失函数的构成,具体是指什么呢?
AI×CAE中的损失函数由数据驱动项和物理约束项的加权和构成:
其中 $\mathcal{L}_{\text{data}}$ 是与观测数据的平方误差,$\mathcal{L}_{\text{physics}}$ 是支配方程的残差,$\mathcal{L}_{\text{reg}}$ 是正则化项。权重参数 $\lambda$ 的调整对学习的稳定性和精度有很大影响。
泛化性能与外推问题
请讲讲“泛化性能与外推问题”!
代理模型最大的挑战在于学习数据范围外(外推区域)的预测精度。通过融入物理定律可以改善外推性能,但难以完全保证。
维度灾难
请讲讲“维度灾难”!
当输入参数空间的维度较高时,所需的样本数量会呈指数级增长。通过主动学习(Active Learning)或拉丁超立方采样(LHS)进行高效的样本配置非常重要。
假设条件与适用极限
这个公式不是万能的吗?在什么情况下不能用?
- 学习数据需充分代表分析对象的物理现象
- 输入参数与输出的关系需是平滑的(存在不连续时需要进行区域分割)
- 主要目的是降低计算成本,对于需要高精度的最终验证应结合使用传统型求解器
- 学习数据的质量(网格已收敛、已完成V&V)不足会降低模型的可信度
啊,原来是这样!学习数据是分析对象,原来是这样的机制啊。
无量纲参数与主导尺度
老师,请讲讲“无量纲参数与主导尺度”!
理解支配分析对象物理现象的无量纲参数,是进行适当模型选择和参数设定的基础。
- 佩克莱数 Pe: 对流与扩散的相对重要性。Pe >> 1 时为对流主导(需要稳定化方法)
- 雷诺数 Re: 惯性力与粘性力之比。流体问题的基本参数
- 毕渥数 Bi: 内部传导与表面对流之比。Bi < 0.1 时可应用集总热容法
- 库朗数 CFL: 数值稳定性的指标。显式解法中需要 CFL ≤ 1
啊,原来是这样!分析对象的物理现象,原来是这样的机制啊。
量纲分析验证
请讲讲“量纲分析验证”!
对于分析结果的数量级估计,基于白金汉Π定理的量纲分析非常有效。使用特征长度 $L$、特征速度 $U$、特征时间 $T = L/U$,可以事先估计各物理量的数量级,从而确认分析结果的合理性。
原来如此。那么,只要分析对象的物理现象能够做到,首先就没问题了对吗?
边界条件的分类与数学特征
选择合适的边界条件直接关系到解的唯一性和物理合理性。边界条件不足会导致问题不适定,边界条件过多则会产生矛盾。
AutoML和超参数优化的整体框架我明白了!从明天开始我会在实际工作中注意运用。
嗯,状态不错!实际动手操作是最好的学习方式。有不明白的地方随时可以问我。
超参数优化理论——黑箱优化的数学
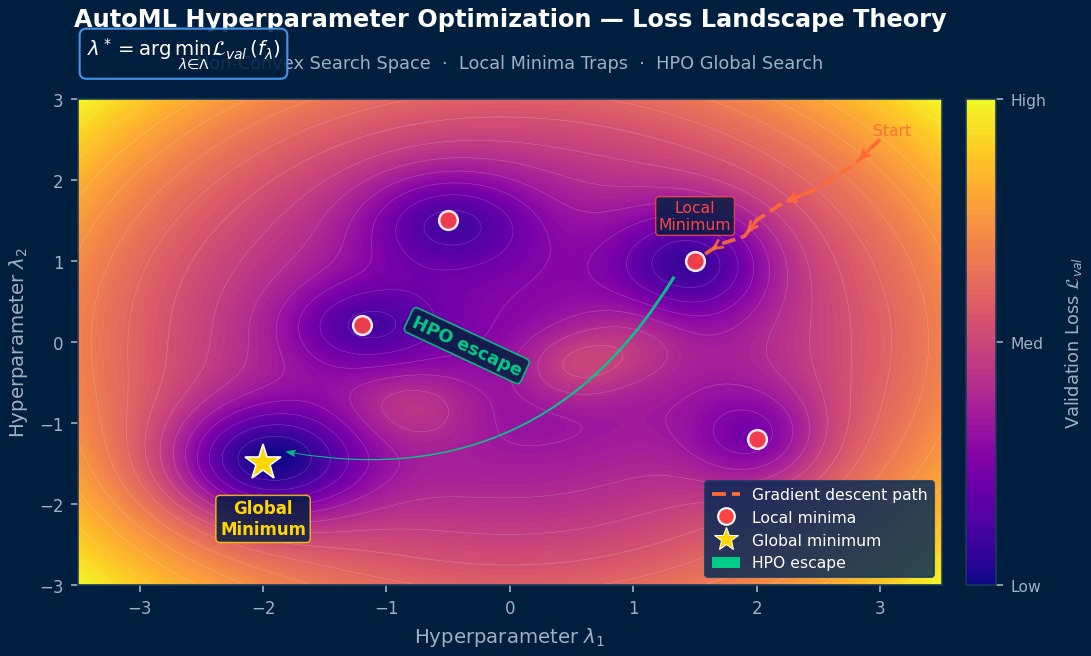
AutoML和超参数优化(HPO)的理论基础是“黑箱优化”。当目标函数(例如CAE代理模型的验证误差)不提供梯度,且一次评估需要数小时时,高效的采样策略就变得至关重要。网格搜索在维度增加时会指数爆炸(维度灾难),随机搜索效率虽高但缺乏保证。贝叶斯优化使用高斯过程(GP)持有目标函数的“信念”,并根据“探索(不确定性高的区域)”和“利用(当前最优解附近)”的平衡来选择下一个采样点。理论上,Expected Improvement(EI)、Upper Confidence Bound(UCB)和Probability of Improvement(PI)是三种经典的获取函数,各自具有不同的探索策略。对于像CAE这样采样成本高的问题,贝叶斯优化具有压倒性优势。
各项的物理意义
- 守恒量的时间变化项:表示目标物理量随时间的变化率。稳态问题中此项为零。【形象比喻】给浴缸放热水时,水位随时间上升——这个“单位时间内的变化速度”就是时间变化项。关闭阀门水位稳定后的状态就是“稳态”,此时时间变化项为零。
- 通量项(流束项):描述物理量的空间输运·扩散。大致分为对流和扩散两种。【形象比喻】对流就像“河流的流动运送小船”一样,物体随流动被运送。扩散就像“墨水在静止的水中自然扩散”一样,物体因浓度差而移动。这两种输运机制的竞争支配着许多物理现象。
- 源项(生成·消失项):表示物理量局部生成或消失的外力·反应项。【形象比喻】在房间里打开暖气,该处就“生成”了热能。化学反应中燃料被消耗,质量就“消失”。这是表示从外部注入系统的物理量的项。
假设条件与适用极限
- 连续介质假设成立的空间尺度
- 材料·流体的本构关系(应力-应变关系、牛顿流体定律等)在适用范围内
- 边界条件在物理上合理且在数学上正确定义
量纲分析与单位制
| 变量 | SI单位 | 注意点·换算备忘 |
|---|---|---|
| 特征长度 $L$ | m | 需与CAD模型的单位制保持一致 |
| 特征时间 $t$ | s | 瞬态分析的时间步长需考虑CFL条件·物理时间常数 |
数值解法与实现
数值手法的细节
具体是用什么算法来求解AutoML和超参数优化呢?
讲解实现AutoML和超参数优化时的数值方法与算法。
老师的讲解很清楚!关于超参数的困惑都烟消云散了。
离散化与计算步骤
这个方程,在计算机上实际是怎么求解的呢?
作为数据预处理,输入特征量的归一化·标准化非常重要。CAE数据各物理量的尺度差异很大,因此需要适当选择Min-Max归一化或Z-score标准化。学习算法的选择需要根据数据量·维度数·非线性程度来选择合适的方法。
实现上的注意点
在实际工作中使用AutoML和超参数优化时,最需要注意的是什么?
通常利用Python生态系统(scikit-learn, PyTorch, TensorFlow)进行实现。通过GPU并行化加速学习、超参数自动调优、交叉验证防止过拟合是实现的关键。对于大规模CAE数据的高效I/O处理,推荐使用HDF5格式。
验证手法
老师,请讲讲“验证手法”!
根据目的区分使用k折交叉验证、留一法、留出法,并使用决定系数R²、RMSE、MAE、最大误差等多方面评估预测性能,这很重要。
我明白前辈说的“交叉验证一定要好好做”的意思了。
代码质量与可复现性
在实际工作中使用AutoML和超参数优化时,最需要注意的是什么?
通过版本管理(Git)、自动测试(pytest)、CI/CD管道的引入来确保代码质量和实验的可复现性。固定依赖库的版本(req
相关主题
なった
詳しく
報告