数据同化手法
数据同化手法的理论基础
概述
老师,我在天气预报中听说过"数据同化",在CAE中也会使用吗?
正是如此。数据同化是指将模拟预测与观测数据进行统计最优融合,提高状态估计精度的手法。在天气预报中,通过融合大气模型与观测点数据来提高预报精度;在CAE中,可以将传感器数据与有限元模拟相结合,实时估计结构物的当前状态。
只用传感器不行吗?
传感器只能获得安装位置的信息。即使在桥梁上粘贴10个应变计,也无法获得数万个节点的信息。使用数据同化,可以通过模拟模型对有限的传感器信息进行空间插值和外推,推断整个结构的状态。
支配方程
从数学角度如何表述?
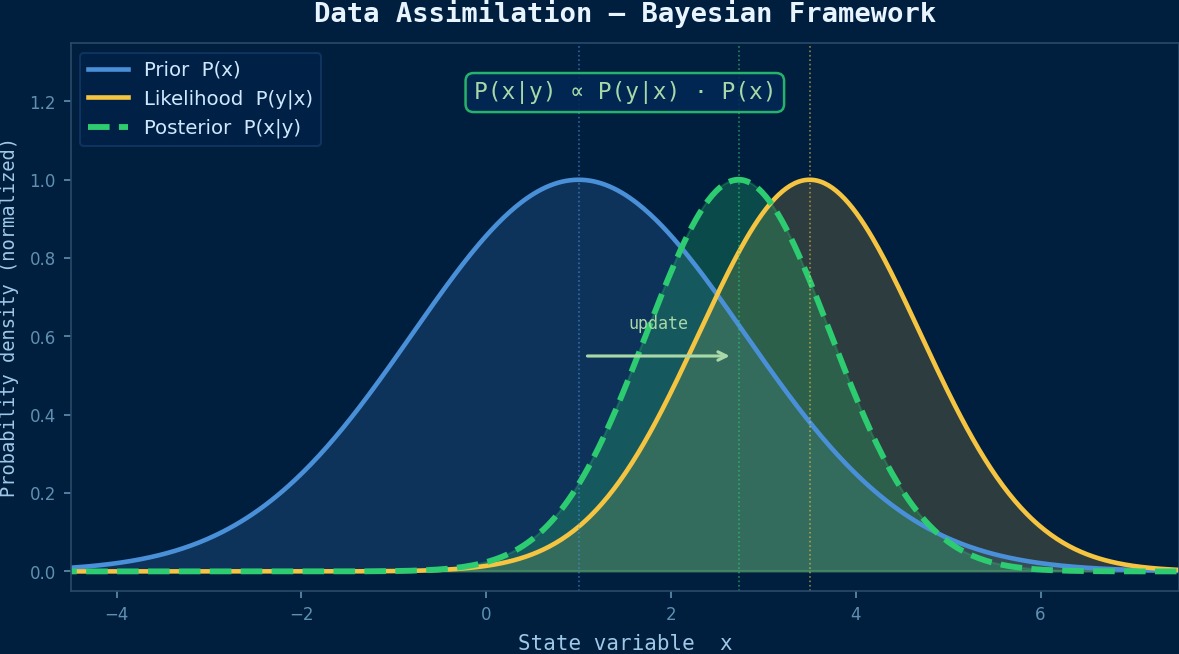
用卡尔曼滤波框架来说明。通过融合状态向量 $\mathbf{x}$ 的预测值(模拟)和观测值,得到分析值(最优估计值)。
其中 $\mathbf{x}^f$ 是预报值,$\mathbf{y}^o$ 是观测值,$\mathbf{H}$ 是从状态空间到观测空间的变换算子。卡尔曼增益 $\mathbf{K}$ 决定了预测和观测的权重分配。
$\mathbf{P}^f$ 和 $\mathbf{R}$ 是什么?
$\mathbf{P}^f$ 是预测的误差协方差矩阵(模拟的不确定性),$\mathbf{R}$ 是观测的误差协方差矩阵(传感器的不确定性)。如果模拟值可信,卡尔曼增益会很小,观测修正也会较弱。反之,如果传感器精度高,会更重视观测端。这种自动的权重调整是数据同化的本质。
主要手法的分类
除了卡尔曼滤波还有其他方法吗?
主要分为两大类。
- 逐次法:集合卡尔曼滤波(EnKF)。用蒙特卡洛集合成员表示预测的不确定性。能够处理非线性问题,但集合大小太小时会出现采样误差
- 变分法:3D-Var/4D-Var。最小化成本函数 $J(\mathbf{x}) = (\mathbf{x}-\mathbf{x}^f)^T\mathbf{B}^{-1}(\mathbf{x}-\mathbf{x}^f) + (\mathbf{y}^o-\mathbf{H}\mathbf{x})^T\mathbf{R}^{-1}(\mathbf{y}^o-\mathbf{H}\mathbf{x})$。4D-Var还考虑时间方向
在CAE中使用哪一种?
结构健康监测中多用EnKF。运行 $N$ 次(集合大小)有限元分析来推断预测的分散,然后用实测值修正。当有限元求解器较慢时,通常与缩减基模型(ROM)结合以降低计算成本。
卡尔曼滤波——从阿波罗计划到结构解析的50年征程
数据同化的理论中枢是卡尔曼滤波(1960年提出)。这个算法最初为阿波罗计划的轨道推估而开发,现已成为气象数值预报的必备工具。日本气象厅结合四维变分法(4D-Var)的独有系统被用于台风路径预测。2010年代以后,将其应用于CAE结构解析的研究急剧增加。例如麻省理工的研究团队发表了利用粘贴于试样上的DIC摄像机全视野位移数据,通过集合卡尔曼滤波逐次同化来"边测边识别"杨氏模量和屈服应力的手法。"分析补充实验,实验修正分析"的这个循环就是数据同化的本质。
数据同化手法的数值计算手法
EnKF的实现步骤
实现EnKF时具体要分几步?
以结构解析数据同化为例来说明。
1. 初始集合生成:对材料参数、荷载条件等设置不确定性,生成 $N$ 个有限元模型($N$ 通常为50~200)
2. 预测步骤:运行每个集合成员的有限元分析,得到状态向量(位移、应力等)
3. 观测算子的应用:从每个成员的状态计算"如果有传感器会看到什么"
4. 更新步骤:计算卡尔曼增益,用实际观测值与差异来修正整个集合
5. 统计量计算:修正后集合的平均值为最优估计值,方差为估计的不确定性
有限元要运行50到200次?计算成本不是非常高?
所以降低计算成本是重要课题。有三个对策。
- ROM化:用POD(固有正交分解)对有限元模型降维,加快 $N$ 次计算
- 局部化:限制卡尔曼增益的空间影响范围,消除不需要的远距离相关
- 膨胀:防止集合分散度过小而导致预测倍增,对协方差进行膨胀处理
变分法的实现
变分法如何实现?
4D-Var需要有限元求解器的伴随方程(adjoint)。用伴随法高效计算成本函数的梯度,用准牛顿法(如L-BFGS)进行优化。伴随求解器的实现较困难,但用于灵敏度分析和反演问题也有价值。不过,大多数商用有限元求解器没有伴随功能,与自动微分(AD)工具的联合使用比较现实。
CAE与的整合流程
如何整合到现有的CAE工作流中?
通常在Python上进行整合。有限元求解器的批处理脚本、EnKF滤波逻辑、传感器数据的采集和预处理都用Python控制。filterPy和DANEXT等开源数据同化库可以参考。
| 组件 | 作用 | 工具示例 |
|---|---|---|
| 有限元求解器 | 预测计算 | CalculiX, Code_Aster, Abaqus |
| DA框架 | 滤波 | filterPy, DAPPER, OpenDA |
| ROM生成 | 降低计算成本 | pyMOR, RBniCS |
| 可视化 | 结果确认 | ParaView, matplotlib |
能实现实时处理吗?
经过ROM化可以在数秒内完成滤波。但必须事先充分验证ROM相对于全模型的精度是否足够。
集合卡尔曼滤波(EnKF)——用蒙特卡洛处理不确定性
扩展卡尔曼滤波(EKF)依赖线性近似,对于非线性较强的CAE问题精度不足。于是出现了集合卡尔曼滤波(EnKF)。从初始状态的概率分布生成数十到数百个"集合成员"(样本状态),在物理模拟中演化这些成员,同时逐次用观测数据修正。实现的关键在于集合大小的选择:大小不足会产生"采样误差",太大又会计算成本爆炸。在流体分析的实际应用中经常出现自由度数×集合大小超过内存上限的情况,常用的对策是用局部化技术限制空间相关范围。
数据同化手法的实务应用
实务应用步骤
在项目中实际应用数据同化的步骤是什么?
首先选择应用对象。数据同化适用于"有模拟模型但参数不确定,需要用有限传感器数据修正"的情况。
1. 构建有限元模型:按常规方法建立有限元模型,对已知荷载条件进行V&V
2. 识别不确定性:定量化材料常数公差、荷载变动范围、边界条件的不确定性
3. 传感器规划:优化传感器安装位置和数量。信息矩阵最大化可作为指标
4. 选择和实现DA手法:根据计算成本和精度要求在EnKF和变分法中选择
5. 孪生实验:先用模拟数据生成"伪观测"来验证DA性能
6. 实测数据应用:孪生实验确认无问题后,切换到实际传感器数据
孪生实验是什么?
在已知真实状态的条件下测试DA性能的试验。用某个参数集运行有限元得到"真实解",加上噪声生成伪观测,然后用DA推断值与真实值比较,验证手法的合理性。在切换到实数据前是必须做的一步。
最佳实践
成功的秘诀是什么?
应用案例
在哪些领域应用过?
风力涡轮机疲劳监测——数据同化现场应用案例
丹麦大型风力发电机制造商Vestas已将数据同化正式纳入海上风力涡轮机叶片疲劳分析。通过在叶片根部安装的加速度传感器和应变计获得实时数据,逐次同化到有限元模拟中,在实际运行条件下精准推断疲劳损伤积累。与过去采用设计时平均风况假设的保守计算相比,数据同化使得能够按个别涡轮机的实际使用情况定制寿命预测。结果是计划外停机减少40%,预防性维护成本大幅下降。应用中的最大困扰是传感器的持续标定管理——盐碱环境和振动导致的传感器经年劣化是实务上最大的瓶颈。
数据同化手法的软件比较
工具与框架
请介绍能实现数据同化的工具。
商用和开源都列举一下。
| 工具 | 类型 | 特点 |
|---|---|---|
| Ansys Twin Builder | 商用 | ROM基础的数字孪生配备DA功能 |
| MATLAB UKF/EKF | 商用 | 系统识别工具箱实现卡尔曼滤波 |
| OpenDA | 开源 | Java/Fortran基础的通用DA框架 |
| DAPPER | 开源 | Python的DA实验和基准测试库 |
| filterPy | 开源 | 轻量级卡尔曼滤波实现 |
| pyDA | 开源 | EnKF/3D-Var的Python实现 |
商用CAE求解器的整合情况如何?
Abaqus用Python API能轻易实现求解器的批处理执行,容易集成到EnKF循环。Ansys Mechancial也可通过ACT扩展或PyMAPDL进行控制。Code_Aster在Salome-Meca平台上有Python整合功能,与DA的兼容性较好。
选择指南
如何选择?
重要的是,DA框架本身不是瓶颈——有限元求解器的接口开发才是主要工作量。
气象业界的数据同化软件进入CAE——DALEC和OpenDA
数据同化软件长期以来是气象和海洋领域专属的,但面向CAE应用的开源工具在增加。荷兰代尔夫特理工大学发起的"OpenDA"代表性强。最初是海洋模型同化库,现已通用化且完善了与有限元/CFD的接口。商业方面,法国达索系统的Simulia在Abaqus周边工具中展开了数据同化功能,在数字孪生的框架下销售。在物理模型未完全确立的新材料和复合材料领域,美国防部资助的DTAP(数字孪生应用平台)等政府主导项目也值得关注。选择时"与自己模拟器的耦合便利性"是最大的评价轴。
数据同化手法的先进研究
最新研究动向
数据同化的前沿研究在做什么?
有几个重要方向。
机器学习与数据同化的融合
出现了直接学习卡尔曼增益的"神经网络卡尔曼滤波",以及用LSTM学习模型误差从而修正预测的手法。传统DA依赖线性化和高斯假设,神经网络方法可以放宽这些约束。
高维状态空间的应对
对数百万自由度的有限元模型进行DA会面临计算量爆炸。随机SVD的在线降维、张量分解压缩集合表示等技术正在研究中,以确保可扩展性。
与数字孪生的关系怎样?
数据同化是数字孪生的核心技术。物理模型与传感器数据的持续同步正是数字孪生的定义本身。今后随着IoT的普及,传感器数据会爆炸式增长,高速大规模DA的需求势必不断上升。
作为反演问题的参数估计
用DA同时推断未知的材料参数和边界条件的"联合状态-参数估计"正在实用化。例如通过传感器数据从运行中的涡轮叶片逐次更新裂纹扩展参数,实时预测剩余寿命的研究。
该领域演进的图景
CAE技术的进化类似"地图的历史"。手绘地图(经验设计)→印刷地图(传统CAE)→导航仪(自动化CAE)→智能手机实时导航(AI整合CAE),逐步朝"更快、更精准、更简便"的方向发展。
数据同化手法的故障排查
常见问题与对策
实现数据同化后如果不顺利,该检查什么?
介绍典型故障。
1. 滤波器发散
症状:推定值随时间与观测数据偏离越来越远。
原因和对策:
- 集合大小过小。最少50,最好100以上
- 膨胀系数设置。协方差被低估会让滤波器过度自信,忽视观测。试试 $\rho = 1.01$~$1.10$ 的膨胀
- 模型偏差存在。系统误差无法用滤波器修正。将偏差项加入状态向量
2. 推定值变得非物理
症状:推定杨氏模量为负,或温度出现非现实值。
原因和对策:
- 参数约束未设定。用对数变换或Sigmoid变换将值限制在物理可行范围
- 观测算子的线性化误差过大。改用迭代EnKF(IEnKF)
3. 计算成本不现实
症状:全部集合的有限元运行耗时数天。
对策:
- 用POD基ROM加速各成员计算
- 用域局部化降低状态向量维数
- 并行计算同时运行多个集合成员
观测误差设置错误会怎样?
将 $\mathbf{R}$ 设得太小,滤波器会过度信任有噪音的观测而振荡。设得太大,观测信息利用不足。根据传感器规格书提供的精度信息设置,用孪生实验验证合理性是王道。
4. 传感器位置不佳
症状:部分状态变量的推定精度特别差。
对策:
- 进行观测能控性分析,确认传感器信息影响全状态变量
- 基于D-最优设计或A-最优设计进行传感器位置优化
观测数据会"说谎"——传感器故障与数据同化的相容性问题
数据同化实装中常常遇到的坑是"传感器故障时的模型破坏"问题。卡尔曼滤波视观测数据为"接近真实的信号",传感器异常会导致整个模型被污染。某座桥梁结构健康监测系统就遭遇过,闪电产生的瞬间噪声让卡尔曼滤波的协方差矩阵发散,此后推定值完全破坏的事故。对策是用创新项(观测与模型预测的差异)大小提前检测异常值,将可疑数据从同化中排除的门控处理必不可少。用χ²检验验证创新项统计合理性是标准手法,是否实装这一功能大幅影响实际系统的稳定性。
是否在结构分析的收敛问题或计算成本上感到困扰?— Project NovaSolver正致力于解决实务人士日常面临的这些课题。
请告诉我们数据同化手法实务中的课题
Project NovaSolver旨在解决CAE工程师日常面临的课题——设置的复杂性、计算成本、结果解释——。您的实务经验将成为更好工具开发的源动力。
联系我们(准备中)