数字孪生与机器学习
数字孪生与ML理论基础
概述
我最近经常听到数字孪生这个词,能解释一下它与CAE的关系吗?
数字孪生是指将实世界物理系统的虚拟副本构建为仿真模型,通过与传感器数据的同步来实时监测和预测系统状态的技术。将CAE物理模型与机器学习相结合,可以实现高速预测和自适应更新。
它与普通的CAE仿真有什么区别?
关键区别在于它是"活的"。普通CAE在设计阶段执行一次就结束了,但数字孪生在运行过程中不断吸收传感器数据并持续更新自身。这样就可以应对老化、意外荷载和环境变化。
支配方程
用数学形式怎么表示?
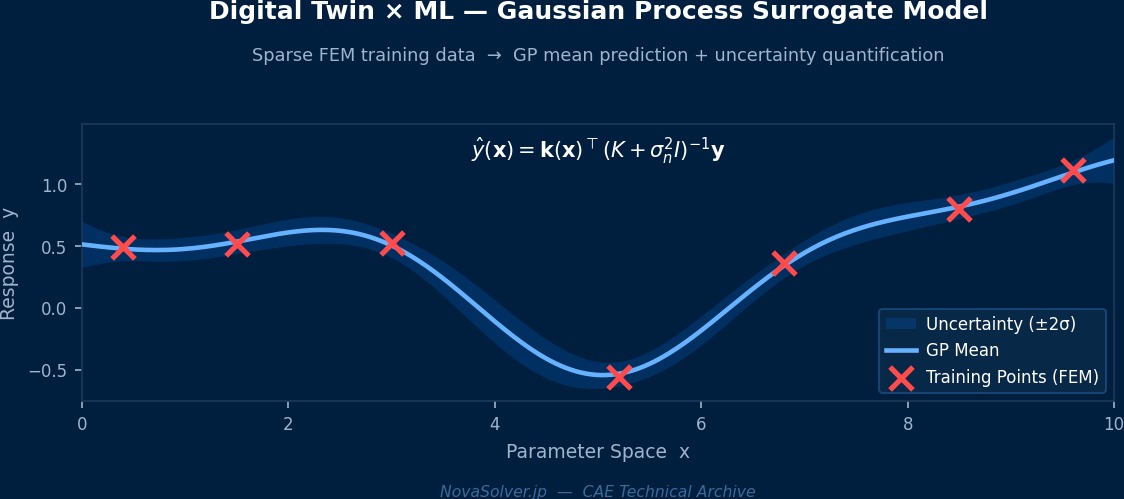
系统状态 $\mathbf{x}_k$ 遵循时间演变方程,观测值 $\mathbf{y}_k$ 是其部分测量值。
其中 $f$ 是物理模型(有限元法等),$\mathbf{u}_k$ 是输入(荷载等),$\mathbf{w}_k$ 是模型误差,$h$ 是观测算子,$\mathbf{v}_k$ 是观测噪声。ML用作 $f$ 的高速近似(代理模型)或模型误差 $\mathbf{w}_k$ 的学习。
加入ML有什么好处?
直接使用有限元法的 $f$ 无法满足实时更新的时间要求。用ML近似 $f$ 可以实现秒级预测。此外,物理模型无法完全表示的老化机制和环境依赖性可以从数据中学习。
物理约束方法
怎样组合物理模型和ML?
有三种模式。
1. 混合型: 用ML修正物理模型的输出。$\hat{y} = f_{\text{physics}}(x) + f_{\text{ML}}(x, \text{residual})$
2. 代理型: 用ML完全替代物理模型。速度快但外推性有问题
3. 物理约束嵌入型: 像PINNs一样把物理规律嵌入ML模型的损失函数
实用上混合型最可靠。物理模型捕捉全局行为,ML修正残差。
数字孪生的定义争议——"孪生"有多"活"?
"数字孪生"这个术语,实际上按人的理解方式差异很大。NASA的定义是"实时反映实机状态的高保真仿真",但制造业的现实多数停留在"3D CAD模型绑定传感器数据的仪表板"。理论上构建真正的数字孪生需要四样齐全:物理模型、数据同化、ML代理、不确定性量化。GE的燃气轮机数字孪生是其中最先进的,单台发动机有数千个传感器,与300多个有限元子模型实时同化。但维护费用据说每年要数亿日元规模,这说明"真正的DT"有多重。
数字孪生与ML数值计算方法
实现架构
数字孪生系统怎样构成?
整理一下主要组件。
| 层 | 组件 | 作用 |
|---|---|---|
| 数据采集层 | IoT传感器、SCADA | 实时获取温度、应变、振动等 |
| 通信层 | MQTT、OPC-UA | 传感器数据到云/边缘的传输 |
| 模型层 | FEM + ROM + ML | 物理预测和高速推理 |
| 同化层 | EnKF、粒子滤波 | 用传感器数据更新模型 |
| 可视化层 | 3D仪表板 | 状态可视化和告警 |
ROM怎样构建?
POD(本征正交分解)是标准做法。多次运算完整有限元解得到快照矩阵,用SVD提取主要基向量。百万自由度的模型往往只需10-50个基向量就能捕捉90%以上的能量,这样计算速度提升万倍以上。
ML模型的学习和更新
ML模型的训练数据怎样获得?
通常分两阶段。
离线学习: 设计阶段大量执行参数化有限元分析,建立参数-响应数据集对ML模型进行预训练。用拉丁超立方体(LHS)有效覆盖参数空间。
在线学习: 运行开始后,用实际传感器数据逐次更新模型。用转移学习或微调对少量实数据进行适配。
在线学习是实时进行的吗?
不一定实时。多数情况下按日或按周进行批量模型更新。实时性要求来自数据同化(状态估计)部分,模型参数更新的周期可以相对宽松。
边缘部署注意事项
想在现场的边缘设备而不是云上运行,怎样处理?
模型轻量化是关键。输出为ONNX格式用ONNX Runtime推理、整数量化(INT8)轻量化计算、TensorRT优化GPU推理。推理计算量控制在100MFLOPS以内的话,像NVIDIA Jetson这样的边缘设备就能达到毫秒级响应。
代理模型让数字孪生"加速"——FNO vs POD-ROM
支撑数字孪生实时性的是代理模型(代替模型)。全有限元每步运算在计算上不可能,所以需要轻量级近似模型加速。传统是POD(本征正交分解)基础的ROM(降阶模型),但非线性强的问题精度不足。2020年代引发关注的是傅里叶神经算子(FNO)。MIT×Caltech的FNO是"函数到函数映射"的学习架构,作为纳维-斯托克斯方程代理比传统方法快1000倍的案例也有。Ansys SimAI也采用类似思想,数小时的CFD解析可以在数秒内近似,公开演示令人印象深刻。
数字孪生与ML实务应用
项目启动步骤
数字孪生项目从哪里开始?
一开始想做太大的话会失败。分步骤进行是铁律。
阶段1: 价值验证(PoC) — 单一组件、少量传感器、简易模型验证"预测是否与实测相符"。周期3-6个月
阶段2: 试点运行 — 在实际运行环境积累数据,分步改进模型。构建在线学习机制。周期6-12个月
阶段3: 全面展开 — 拓展到多个组件、多物理场。确立运维体制
PoC失败的案例有吗?
最多的是"数据不足"。传感器位置不当、采样频率太低或者数据质量差。PoC前的传感器规划很关键。
最佳实践
成功的秘诀是什么?
应用案例
有具体的应用案例吗?
| 行业 | 对象 | 效果 |
|---|---|---|
| 航空 | 喷气发动机涡轮叶片 | 余寿预测优化维修计划 |
| 风力发电 | 风机驱动链 | 故障预兆检测避免突然停机 |
| 桥梁 | 钢桥疲劳损伤 | 应变传感与有限元同化定位损伤位置 |
| 汽车 | 电池组 | 温度分布预测和老化监测 |
| 工厂 | 压力容器 | 蠕变寿命在线更新 |
波音787数字孪生——追踪复合材机体的"衰老"
航空器机体维保管理中数字孪生得到全面应用。波音为787部署的系统,每次飞行记录数万通道的FDR(飞行数据记录)数据,结合结构有限元仿真追踪复合材外板的疲劳损伤。这样就从传统的"全机统一检修计划"转变为"依据该机体实际使用的个别计划"。实装中最大课题是"由谁更新模型"的体制建立。机体设计部门、MRO(维修部门)、IT系统部门纵向割裂,仿真器版本管理与数据管线协调成为技术以上的组织难题。
数字孪生与ML软件对比
主要平台
数字孪生的商用工具有哪些?
分为CAE类和IoT类两个系统。
| 平台 | 提供商 | 特点 |
|---|---|---|
| Ansys Twin Builder | Ansys | 从ROM生成到部署一体支持 |
| Siemens Simcenter | Siemens | 与MindSphere的IoT整合 |
| Dassault 3DEXPERIENCE | Dassault | 与PLM整合、云原生 |
| Azure Digital Twins | Microsoft | 云基础设施、IoT Hub连接 |
| AWS IoT TwinMaker | Amazon | 3D可视化、Grafana集成 |
| NVIDIA Omniverse | NVIDIA | 实时3D、物理仿真联动 |
应该选CAE厂商还是IT厂商?
物理模型精度优先的话选CAE厂商有利。现有有限元资产可以直接利用。反之,海量IoT数据处理和可扩展性优先就选云厂商。理想是两者相结合。
成本结构
数字孪生部署成本多少?
主要费用项目三点。
1. 传感器/IoT基础设施: 每套系统数百万到数千万日元。随传感器种类和数量而定
2. CAE模型构建和ROM化: 数百万到数千万日元。依赖现有模型的可用程度
3. 平台使用费: 年数十万到数百万日元。云按量计费
最大成本实际是人力,需要CAE工程师与数据科学家的协作体制费时费力。
Siemens Xcelerator vs Ansys Twin Builder——数字孪生平台竞争
数字孪生平台市场现在西门子和安世亚斯展开激烈竞争。Siemens Xcelerator把NX/Teamcenter与MindSphere云整合,实现产品生命周期管理(PLM)与分析一体化的生态战略。Ansys Twin Builder优势在横跨有限元/流体/电路仿真的"系统仿真",Python脚本联动也容易。另一方面,MathWorks的Simulink在控制工程师中根深蒂固,数字孪生的控制环节强。实际大型汽车厂三种工具按用途分工使用的例子很常见,FMI/FMU格式对应的互操作性成为选型重要指标。
数字孪生与ML前沿研究
最新研究动向
数字孪生研究最前沿怎样发展?
有三大趋势。
自主数字孪生
无人干预的自动更新、自优化系统研究。强化学习代理学习模型更新策略,自动判断"何时、哪部分、更新幅度"。
多保真融合
不同精度级别的模型(高精度有限元、中精度ROM、低精度经验式)动态切换。实时平衡计算成本与精度。急剧状态变化检出则切换高精度,定常状态用轻量模型监测。
数字孪生联成
多个组件数字孪生连结建立系统级数字孪生研究。比如发动机的叶片、转子、轴承数字孪生联成评价发动机整体健康性。
标准化动向如何?
ISO 23247(数字孪生框架)已制定,术语和参考架构得以定义。产业界数字孪生协会(DTC)推进最佳实践共享。今后数字孪生品质保证和认证框架会进一步完善。
量子计算×数字孪生——未来十年的前奏
可能从根本上解决数字孪生"计算瓶颈"的技术,是量子计算与融合研究。IBM与博世共同项目在量子变分算法(VQE)上解电动马达电磁场分析的一部分原型开发。现在还远不如经典超算,但量子比特增加的话,有限元矩阵特征值问题有望指数加速。另一方面,对CAE更现实的近未来技术是"量子启发"算法。富士通的数字退火机用FPGA模拟量子组合优化,自动车零件的拓扑优化问题大幅加速有实绩。
数字孪生与ML故障排除
常见问题和解决方案
数字孪生运行中易出现的故障是什么?
主要故障列举如下。
1. 模型与实测偏差不断增大
症状: 运行初期吻合的预测,随时间越来越偏离。
原因与对策:
- 模型未反映经年劣化。增加老化参数在线估计机制
- 传感器漂移。定期标定、冗余传感器交叉检验
- 运行条件超出设计假定。明示模型适用范围,范围外给出警告
2. 实时性无法确保
症状: 模型响应缓慢,无法用于监测。
对策:
- 削减ROM基向量数量(确认精度与速度均衡)
- GPU或FPGA加速ML推理
- 降低更新频率(可能秒级更新改为分级)
3. 数据管道障碍
症状: 传感器数据中断时模型失控。
对策:
- 数据缺失时转为纯模型预测(自动切换预测模式)
- 输入模型前进行数据质量检查,滤除异常值
- 通信冗余化(有线+无线备份)
增加传感器数量能提高精度吗?
不一定。冗余传感器增加信息很少,应按信息论原则优化传感器配置。传感器质量(精度、稳定性、响应速度)往往比数量更重要。
4. 模型更新时稳定性
症状: 在线学习更新模型后预测突然不稳定。
对策:
- 学习率充分小化。防止灾难性遗忘(catastrophic forgetting)
- 更新前后用已知基准案例比较预测,确认性能无劣化
- 实现回滚功能,问题时恢复旧模型
数字孪生的"时间延迟"问题——与延迟的格斗
说数字孪生"实时"时,"实时"程度因用途差异很大。机床制控需数毫秒内,桥梁长期劣化监测1小时延迟也可以。常见错误是低估"传感器数据收集→前处理→同化→分析→结果显示"全管道的总延迟。某汽车工厂焊接机器人的实时有限元更新系统试验中,云通信延迟远超预期3倍,无法满足控制环。解决需要向边缘计算(工厂内服务器)转移,加上ML代理轻量化重分析两手齐备。"云优先设计"必须事先验证通信成本与延迟。
为结构分析收敛问题或计算成本苦恼吗?— Project NovaSolver是以解决实务工作者日常面临的课题为目标的研发项目。
告诉我们您在数字孪生与ML实务中感受的课题
Project NovaSolver旨在解决CAE工程师日常面临的课题——设置的复杂性、计算成本、结果解释。您的实务经验将成为开发更好工具的动力。
联系我们(筹备中)价值
更详细
错误