CAE数据异常检测
理论与物理
概述
老师,怎么才能发现仿真结果里有没有混入奇怪的数据呢?
这正是CAE数据异常检测的领域。这是一种从大量仿真结果或实测数据中,自动检测出偏离正常模式的行为的技术。利用自编码器或孤立森林等机器学习算法,捕捉人眼容易忽略的微妙异常。
比如能检测出什么样的“异常”呢?
举些具体例子,比如结构分析中局部应力非物理性地急剧升高的情况,CFD非定常计算中数值突然开始发散的前兆,或者实验数据与仿真结果的差异突然增大的部位等。也能用于检测传感器故障。
控制方程
用数学公式表示异常检测的话会是什么样子?
使用自编码器时,将输入数据 $\mathbf{x}$ 用编码器 $E$ 压缩到低维,再用解码器 $D$ 复原。正常数据的话重构误差小,异常数据则误差大。将此作为异常分数使用。
也就是说“普通数据能很好复原,但奇怪的数据就复原不了”对吧。
正是如此。训练时的重构误差损失函数是这样的。
孤立森林则是另一种方法,它利用了数据空间被随机分割时,异常数据能以较少的分割次数被孤立出来的特性。
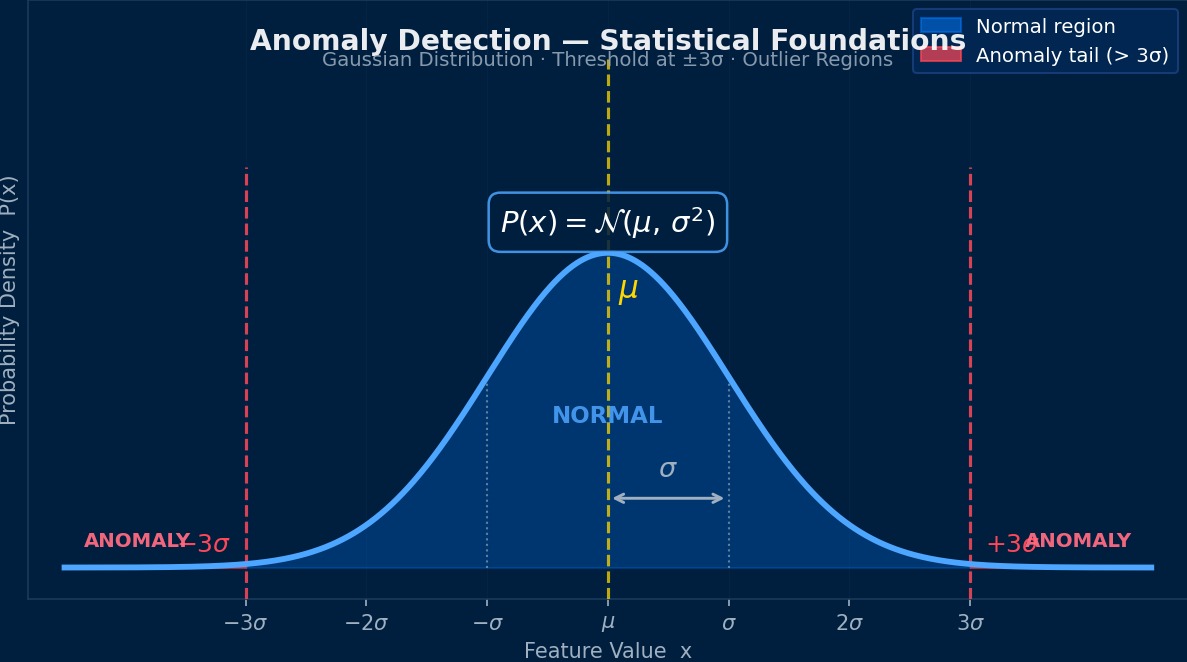
理论基础
异常检测在统计学上处于什么位置呢?
本质上是“学习正常数据的概率分布,检测偏离该分布的数据”的问题。从密度估计的角度看,是估计正常数据的概率密度 $p(\mathbf{x})$,将低于阈值 $\tau$ 的数据判定为异常。但CAE数据具有高维且非线性的结构,仅靠简单的高斯分布假设是不够的,需要神经网络进行非线性映射。
如果“正常”的定义模糊不清该怎么办?
问得好。无监督异常检测只使用正常数据进行学习,但半监督方法会利用少量已知的异常标签。在CAE的语境下,典型的用法是将网格收敛后的高质量仿真结果作为“正常”进行学习,检测收敛不足或由bug导致的结果作为“异常”。
假设条件与适用极限
并不是什么数据都能用吧?
有几个重要的限制条件。首先,需要有足够量的正常数据。如果未能覆盖正常模式的多样性,就会将未知的正常模式误判为异常。此外,如果无法事先预想异常的种类,就只能依赖无监督方法,但会面临检测灵敏度与误报率之间的权衡难题。阈值的设定离不开领域知识。
CAE特有的难点有哪些?
有的。CAE数据各物理量的尺度完全不同(应力为10^8 Pa,位移为10^-3 m等),因此必须进行适当的归一化。另外,由于网格不同,即使同一物理现象数据表现形式也会变化,因此设计网格无关的特征量是个课题。
异常检测的理论根源——从统计学到流形学习
CAE数据的异常检测,原本是发端于1950年代质量管理(SPC:统计过程控制)的一个不起眼的领域。从休哈特控制图的“平均值±3σ之外即为异常”这一简单规则,进化到马氏距离、自编码器、孤立森林,是近20年的事。理论上有趣的是“学习正常状态流形”这一思路。将偏离正常数据所张成的低维空间的点视为异常的想法,与非线性降维(UMAP/t-SNE等)理论紧密相连。以流体仿真为例,就是识别偏离正常涡流行为所张成流形的速度场为“异常”,这与物理直觉也容易一致。
各项的物理意义
- 守恒量的时间变化项:表示目标物理量随时间的变化率。稳态问题中此项为零。【形象比喻】给浴缸放水时,水位随时间上升——这个“单位时间内的变化速度”就是时间变化项。关闭阀门水位保持恒定的状态就是“稳态”,时间变化项为零。
- 通量项(流束项):描述物理量的空间输运·扩散。大致分为对流和扩散两种。【形象比喻】对流是“河流水流运送小船”那样,物体随流动被运送。扩散是“墨滴在静止水中自然散开”那样,物体因浓度差而移动。这两种输运机制的竞争支配着许多物理现象。
- 源项(生成·消失项):表示物理量局部生成或消失的外力·反应项。【形象比喻】在房间里打开暖气,该处就“生成”了热能。化学反应中燃料被消耗,质量就“消失”。表示从外部注入系统的物理量的项。
假设条件与适用极限
- 连续介质假设成立的空间尺度
- 材料·流体的本构关系(应力-应变关系、牛顿流体定律等)在适用范围内
- 边界条件物理上合理且数学上正确定义
量纲分析与单位制
| 变量 | SI单位 | 注意事项·换算备忘 |
|---|---|---|
| 特征长度 $L$ | m | 需与CAD模型的单位制保持一致 |
| 特征时间 $t$ | s | 瞬态分析的时间步长需考虑CFL条件·物理时间常数 |
数值解法与实现
主要算法的实现
具体应该实现什么样的算法呢?
我们来整理一下代表性的方法。
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 自编码器 | 重构误差 | 擅长高维数据 | 阈值设定困难 |
| 孤立森林 | 随机分割下的孤立度 | 学习速度快,可扩展性强 | 对局部异常较弱 |
| 单类SVM | 超平面对正常区域的包围 | 理论上稳健 | 大规模数据计算成本高 |
| LOF | 局部密度比较 | 对局部异常强 | 受维度灾难影响 |
| VAE | 潜在空间概率分布的偏离 | 可量化不确定性 | 学习易不稳定 |
对于CAE数据,推荐用哪个呢?
场数据(应力场、温度场等)适合用自编码器或VAE。其中能利用2D/3D空间结构的卷积自编码器尤其有效。另一方面,对于参数空间的异常检测(设计参数与响应关系的偏离),孤立森林或LOF更实用。
数据预处理流程
实现时首先应该做什么?
数据预处理决定成败。CAE数据特有的流程如下。
1. 缩放: 对各物理量分别进行Min-Max归一化或Z-score归一化。如果要混合应力和位移数据,这是必须的
2. 特征提取: 从场数据中提取标量特征(最大值、平均值、标准差、梯度大小)的方法,以及将场数据直接当作图像处理的方法
3. 缺失值处理: 剔除或标记发散计算案例中的NaN/Inf值
4. 降维: 也可以先用PCA或t-SNE降维,再进行异常检测
为什么要用HDF5?
要高效读写大规模CAE数据(数万案例,每个案例数百万节点)的NumPy数组,HDF5的分块I/O和压缩功能不可或缺。相比CSV读取,速度提升10倍以上也不少见。
实现的要点
请告诉我用Python编写时的具体技巧。
- scikit-learn的IsolationForest、LocalOutlierFactor可以直接使用
- 用PyTorch搭建自编码器时,瓶颈层的维度很重要。可以从输入维度的1/10〜1/20左右开始尝试
- 批次大小太小会导致学习不稳定,太大则异常特征会被平均化而淹没。32〜128左右是参考范围
- 异常分数的阈值常使用训练数据重构误差的95百分位数或99百分位数
验证方法
异常检测的性能如何评估?
精确率、召回率、F1分数、AUC-ROC是基本指标。但在CAE语境下,异常数据通常极少,因此PR曲线(精确率-召回率曲线)往往比ROC曲线更合适。此外,检测出的异常是否具有物理意义,也需要领域专家进行确认。
自编码器“遗漏”的异常——重构误差的陷阱
使用自编码器进行异常检测的基本思路是“用正常数据训练的模型无法重构异常→重构误差大=异常”。但在实际工作中存在意想不到的陷阱。例如,某汽车制造商的碰撞仿真质量检查中,自编码器将“罕见但正常”的复杂变形模式误判为异常。这是因为模型未能充分学习到正常的多样性。对策方面,使用β-VAE(变分自编码器)对潜在空间进行正则化,或者直接学习正常数据超球面的Deep SVDD等方法被认为是有效的。
低阶单元
计算成本低,实现简单,但精度有限。在粗糙网格上可能产生较大误差。
高阶单元
在同一网格上实现更高精度。计算成本增加,但通常所需单元数会减少。
牛顿-拉弗森法
非线性问题的标准方法。在收敛半径内具有二阶收敛性。以 $||R|| < \epsilon$ 作为收敛判据。
时间积分
离散化的形象比喻
数值解法类似于“用数码相机拍照”。将现实中连续的风景(连续体)用有限个像素(单元/网格)来表现。提高像素数(网格密度)画质(精度)会提升,但文件大小(计算成本)也会增加。找到最佳平衡点是实际工作中的关键。
实践指南
分析流程的整体概览
在实际工作中进行CAE数据异常检测时,该从哪里入手?
整体流程是这样的。
1. 明确目的: 决定将什么定义为异常。是检测求解器的数值错误,还是检测设计参数的偏离,方法会不同
2. 构建正常数据库: 收集经过网格收敛确认、V&V验证的可靠仿真结果
3. 特征设计: 根据对象选择标量特征还是场数据
4. 模型学习与阈值确定: 通过交叉验证确认泛化性能,同时平衡误报率与漏报率
5. 运用与持续改进: 定期用新数据更新模型
构建正常数据库看起来是最难的。
没错。正常数据的质量决定了整个模型的可信度。实际工作中,使用经验丰富的CAE工程师确认过的“有保证”的分析结果作为正常标签。只采用经过网格收敛确认、力平衡确认、与理论解比较后的结果,这是铁律。
最佳实践
请告诉我避免失败的技巧。
- 明确异常检测模型的适用范围。不要将其应用于与学习所用的分析类型(线性静力分析、热传导等)不同的分析
- 阈值不要固定,也可以考虑根据参数空间的位置自适应变化。应力集中部位与均匀应力部位的“正常”范围不同
- 检测出的异常必须有人工确认的流程。完全自动化目前风险还很高
- 将异常检测结果作为日志积累,分析误报模式,持续改进模型
应用案例
实际在什么场景下使用呢?
代表性的应用场景如下。
| 应用场景 | 检测对象 |
|---|