网格质量预测模型
概述
老师!今天讨论 网格品質予測模型的話? 是什么内容?
网格质量预测的理论基础
利用机器学习预先预测生成网格的质量指标(长宽比、偏斜度等),从而预先防止不良网格的产生。该方法可自动检测质量缺陷并提供修正建议。
控制方程
用数学公式表示的话就是这样。
嗯…只看公式还是不太明白…这表示的是什么意思呢?
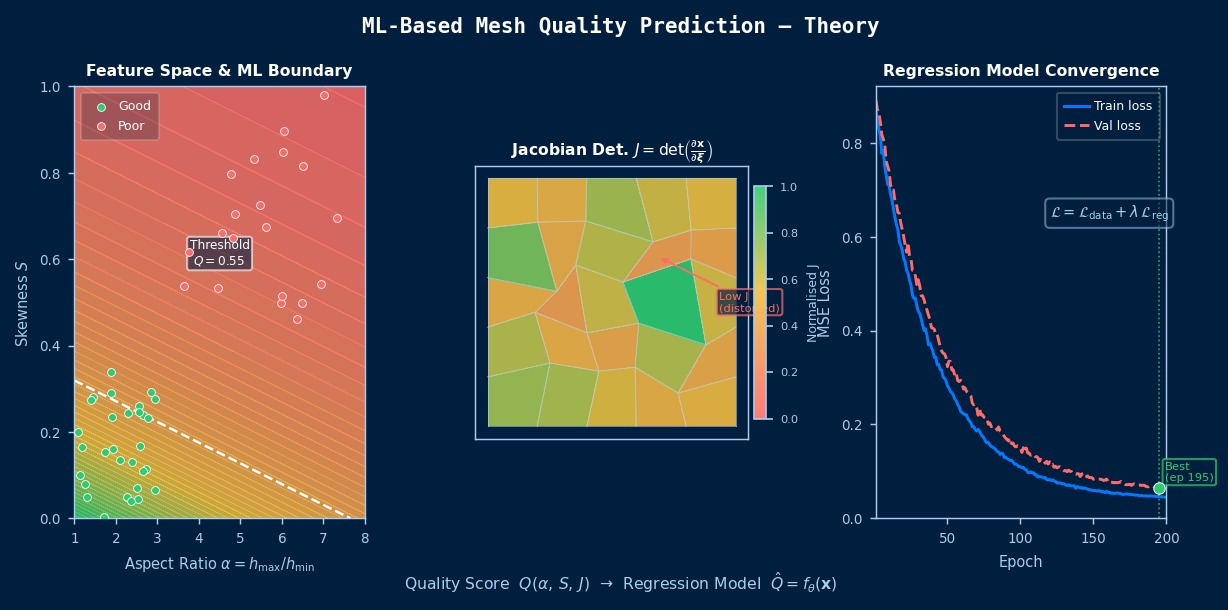
长宽比与偏斜度:
老师的解释很清楚!关于长宽比和偏斜度的困惑都解开了。
理论基础
“理论基础”这个词我听说过,但可能没有真正理解…
网格质量预测模型是旨在融合数据驱动方法与基于物理建模的重要技术。在传统CAE分析中,计算成本是主要的瓶颈,而引入网格质量预测模型可以大幅改善计算效率与预测精度之间的权衡。本方法的数学基础立足于函数逼近理论与统计学习理论,其泛化性能的保证和收敛性的严格分析是理论研究的课题。特别是处理高维输入时的“维度诅咒”是实用化的关键,降维和稀疏性的利用是重要的方法。
适用条件与前提
老师,请给我讲讲“适用条件与前提”!
使用本方法时,需要事先探讨输入数据的质量与数量、模型假设成立的范围、计算资源的限制。为了确认物理合理性,与已知分析解或基准问题的比较验证是不可或缺的。需要基于理论误差评估,对所需精度与计算成本之间的平衡做出恰当判断。
数学定式化的详细
接下来是“数学定式化的详细”!这是什么内容呢?
展示将机器学习模型应用于CAE时的基本数学框架。
损失函数的构成
损失函数的构成,具体是指什么呢?
AI×CAE中的损失函数由数据驱动项和物理约束项的加权和构成:
这里 $\mathcal{L}_{\text{data}}$ 是与观测数据的均方误差,$\mathcal{L}_{\text{physics}}$ 是控制方程的残差,$\mathcal{L}_{\text{reg}}$ 是正则化项。权重参数 $\lambda$ 的调整对学习的稳定性和精度有很大影响。
泛化性能与外推问题
请给我讲讲“泛化性能与外推问题”!
代理模型最大的挑战在于学习数据范围外(外推区域)的预测精度。通过融入物理定律可以改善外推性能,但难以完全保证。
维度诅咒
请给我讲讲“维度诅咒”!
当输入参数空间的维度较高时,所需的样本数量会呈指数级增长。通过主动学习或拉丁超立方采样进行高效的样本配置非常重要。
假设条件与适用极限
如果不了解前提条件就使用,会导致什么样的失败呢?
- 学习数据需充分代表分析对象的物理现象
- 输入参数与输出之间的关系需平滑(存在不连续时需要进行区域分割)
- 主要目的是降低计算成本,对于需要高精度的最终验证应结合使用传统求解器
- 若学习数据质量不足(未进行网格收敛、未进行V&V),模型的可靠性会下降
啊,原来是这样!学习数据是分析对象,原来是这样的机制啊。
无量纲参数与主导尺度
“无量纲参数与主导尺度”这个词我听说过,但可能没有真正理解…
理解支配分析对象物理现象的无量纲参数,是选择合适模型和设置参数的基础。
- 佩克莱数 Pe: 对流与扩散的相对重要性。Pe >> 1 时为对流主导(需要稳定化方法)
- 雷诺数 Re: 惯性力与粘性力之比。流体问题的基本参数
- 毕渥数 Bi: 内部传导与表面对流之比。Bi < 0.1 时可应用集总热容法
- 库朗数 CFL: 数值稳定性的指标。显式解法中需要 CFL ≤ 1
啊,原来是这样!分析对象的物理现象,原来是这样的机制啊。
量纲分析验证
请给我讲讲“量纲分析验证”!
对于分析结果的数量级估计,基于白金汉π定理的量纲分析非常有效。使用特征长度 $L$、特征速度 $U$、特征时间 $T = L/U$,可以事先估计各物理量的数量级,从而确认分析结果的合理性。
边界条件的分类与数学特征
选择合适的边界条件直接关系到解的唯一性和物理合理性。边界条件不足会导致不适定问题,边界条件过多则会产生矛盾。
网格质量预测模型的整体框架我明白了!从明天开始我会在实际工作中留意。
嗯,状态不错!实际动手尝试是最好的学习方式。有不明白的地方随时可以问我。
网格质量指标的“物理意义”——为何长宽比会破坏求解精度
网格质量指标(长宽比、雅可比矩阵、偏斜度等)是从有限元法误差分析中理论推导出的数值。例如,当长宽比(最长边/最短边)变大时,单元的形函数会偏向特定方向,导致刚度矩阵的条件数恶化,从而使方程组的解变得不稳定。理论上,长宽比≤3左右是多数求解器的推荐值,但在边界层网格(流体分析壁面附近)中,则有意允许100以上的长宽比——因为如果物理上流动平行于壁面,问题会退化,即使网格质量低也能成立。当ML判别“质量差的网格”时,算法能否学习到这种“物理上下文依赖”是其真正价值的体现。
数值解法与实现
讲解实现网格质量预测模型时的数值方法与算法。
我明白前辈说的“只有网格质量预测模型一定要认真做”的意思了。
离散化与计算步骤
这个方程,在计算机上实际是怎么求解的呢?
作为数据预处理,输入特征量的归一化/标准化非常重要。由于CAE数据各物理量的尺度差异很大,需要适当选择Min-Max归一化或Z-score标准化。在选择学习算法时,需要根据数据量、维数、非线性程度选择合适的算法。
实现上的注意事项
在实际工作中使用网格质量预测模型时,最需要注意的是什么?
利用Python生态系统(scikit-learn, PyTorch, TensorFlow)进行实现是普遍做法。通过GPU并行化加速学习、超参数自动调优、交叉验证防止过拟合是实现的关键。对于大规模CAE数据的高效I/O处理,推荐使用HDF5格式。
验证方法
老师,请给我讲讲“验证方法”!
根据目的区分使用k折交叉验证、留一法、留出法,并使用决定系数R²、RMSE、MAE、最大误差等多方面评估预测性能,这很重要。
我明白前辈说的“只有交叉验证一定要认真做”的意思了。
代码质量与可复现性
在实际工作中使用网格质量预测模型时,最需要注意的是什么?
通过版本管理(Git)、自动化测试(pytest)、CI/CD流水线的引入,确保代码质量和实验的可复现性。彻底固定依赖库的版本(requirements.txt),使计算环境易于重建。固定随机数种子以确保结果可复现也是重要的实现惯例。
啊,原来是这样!版本管理原来是这样的机制啊。