DeepONet算子学习
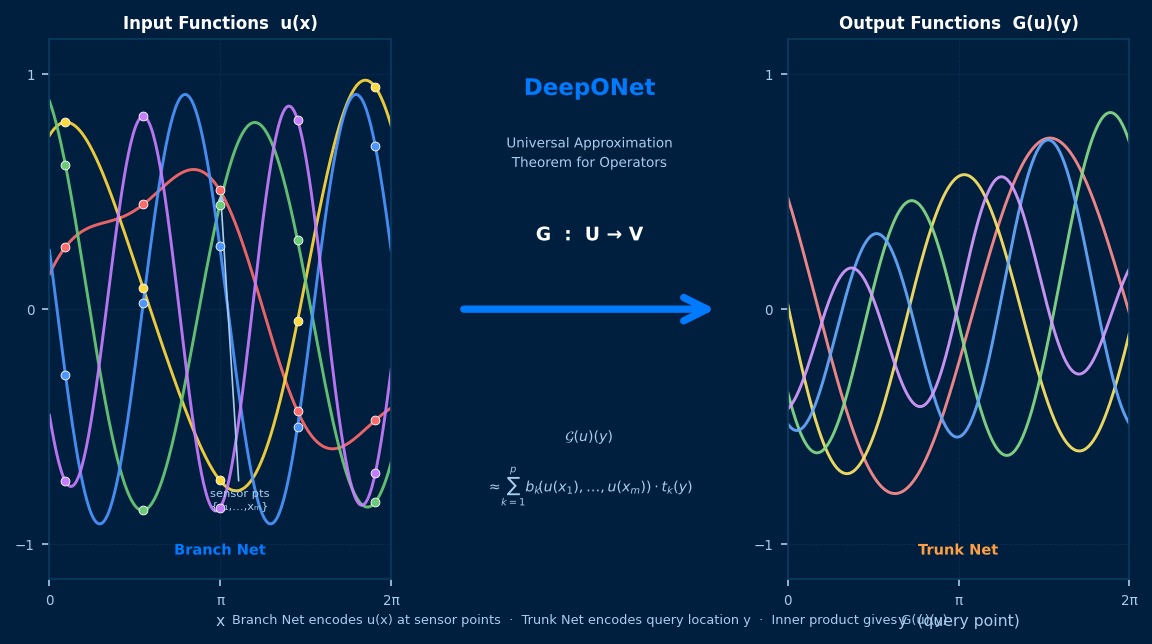
概述
老师!今天是DeepONet算子学习的讲座吧?它是什么样的?
DeepONet算子学习的理论基础
DeepONet是学习函数到函数映射(算子)的架构。用Branch Net编码输入函数,用Trunk Net处理输出位置,结合它们。
那么说,如果函数到函数的映射能够进行,首先就没什么问题吧?
支配方程
用数式表示的话就是这样。
仅看公式还是不太明白…这表示什么呢?
损失函数是:
也就是说在损失函数那里掉以轻心,后面就会吃亏吧。我会牢记于心!
理论基础
听说过"理论基础"这个词,但可能还没完全理解…
DeepONet算子学习是数据驱动方法与基于物理建模的融合方法的结合。在传统CAE分析中,计算成本成为瓶颈,但通过引入DeepONet算子学习可以大幅改善计算效率与预测精度的权衡。本方法的数学基础建立在函数近似理论与统计学习理论之上,泛化性能的保证与收敛性的严格分析成为理论研究的课题。特别是在输入维数较高的情况下,维数灾难的处理是实用的关键,维数降低与稀疏性的活用成为重要的方法。
数学表述的详细内容
接下来是「数学表述的详细内容」呢!这是什么内容?
将机械学习模型应用于CAE时的基本数学框架。
损失函数的构成
损失函数的构成具体是什么意思?
AI×CAE中的损失函数由数据驱动项和物理约束项的加权和构成:
这里 $\mathcal{L}_{\text{data}}$ 是观测数据的平方误差,$\mathcal{L}_{\text{physics}}$ 是支配方程的残差,$\mathcal{L}_{\text{reg}}$ 是正则化项。权重参数 $\lambda$ 的调整对学习的稳定性与精度产生很大影响。
泛化性能与外推问题
请教我"泛化性能与外推问题"!
代理模型的最大课题是学习数据范围外(外推域)的预测精度。虽然通过融入物理规律可改善外推性能,但完全保证很困难。
维数灾难
请教我"维数灾难"!
当输入参数空间维数较高时,所需样本数呈指数增长。主动学习(Active Learning)和拉丁超立方体采样(LHS)进行有效的样本配置非常重要。
假设条件与适用限界
这个公式万能吗?不能用的情况是什么时候?
啊,我明白了!学习数据代表分析对象就是这样的机制。
无量纲参数与主导尺度
老师,请教我"无量纲参数与主导尺度"!
理解支配分析对象的物理现象的无量纲参数是选择适当模型和参数设置的基础。
啊,我明白了!分析对象的物理现象就是这样的机制。
量纲分析的验证
请教我"量纲分析的验证"!
对分析结果的量级推估,基于Buckingham的Π定理进行量纲分析是有效的。使用代表长度 $L$、代表速度 $U$、代表时间 $T = L/U$,事先推估各物理量的量级,确认分析结果的合理性。
那么说,分析对象的物理现象做好了,首先就没什么问题吧?
边界条件的分类与数学特性
听说边界条件要是搞错了,全部都完蛋…
| 种类 | 数学表达 | 物理意义 | 例 |
|---|---|---|---|
| 狄利克雷条件 | $u = u_0$ on $\Gamma_D$ | 变量值指定 | 固定壁、温度指定 |
| 诺依曼条件 | $\partial u/\partial n = g$ on $\Gamma_N$ | 梯度(通量)指定 | 热通量、力 |
| 罗宾条件 | $\alpha u + \beta \partial u/\partial n = h$ | 变量与梯度的线性组合 | 对流传热 |
| 周期性边界条件 | $u(x) = u(x+L)$ | 空间周期性 | 单元体解析 |
适当的边界条件选择直接关系到解的唯一性和物理合理性。条件不足会导致问题不适定,过量的条件会产生矛盾。
哇,DeepONet算子学习真深奥啊…但是得到老师的讲解,总算整理清楚了!
嗯,干得不错!真正的学习就是通过动手实践。如果有不懂的地方,任何时候都可以问我。
"DeepONet学习「算子」是什么意思"——从Chen的通用近似定理出发
1995年,Chen和Chen证明的"算子的通用近似定理"指出神经网络可以以任意精度近似非线性算子。DeepONet(Lu et al. 2021,发表于《Nature Machine Intelligence》)是用深度学习实现这一定理的方法。trunk network学习输出空间的基函数,branch network预测输入函数的系数——这个架构就是学习"函数→函数"映射的机制。不必反复求解PDE,只需一次正向传播就能评估其解算子,这一点是革命性的。
DeepONet算子学习的数值计算方法
在实现DeepONet算子学习时的数值方法与算法进行讲解。
离散化与计算步骤
这个方程在计算机上怎样实际求解呢?
作为数据的预处理,输入特征的正规化和标准化很重要。CAE数据的物理量按量级差异很大,需要根据情况适当选择Min-Max正规化或Z-score正规化。在学习算法的选择上,根据数据量、维数、非线性程度选择合适的方法。
实现上的注意点
在实务中使用DeepONet算子学习时,最需要注意的是什么?
通常使用Python生态(scikit-learn、PyTorch、TensorFlow)进行实现。GPU并行计算加速学习、超参数自动调整、交叉验证防止过度拟合是实现的关键。对于大规模CAE数据的高效I/O处理,推荐使用HDF5格式。
验证方法
老师,请教我"验证方法"!
根据目的区分使用k折交叉验证、留一法、保留法,用判定系数R²、RMSE、MAE、最大误差从多个角度评价预测性能很重要。
前辈说"交叉验证一定要好好做",现在明白那是什么意思了。
代码质量与可重复性
在实务中使用DeepONet算子学习时,最需要注意的是什么?
通过版本管理(Git)、自动测试(pytest)、CI/CD流水线的导入确保代码质量与实验可重复性。依赖库版本的固定(requirements.txt)有助于计算环境的重构。随机数种子的固定以确保结果可重复也是重要的实现习惯。
啊,我明白了!版本管理就是这样的机制。
实现算法的详细内容
想更深入了解计算过程中发生的事情!
神经网络架构
接下来是神经网络架构的讲座。什么内容?
CAE应用中使用的主要架构:
| 架构 | 输入 | 输出 | 应用场景 |
|---|---|---|---|
| 全连接NN (MLP) | 参数向量 | 标量/向量 | 代理模型 |
| CNN | 图像/场数据 | 图像/场数据 | 图像预测 |
| GNN | 图(网格) | 节点值 | 网格基预测 |
| DeepONet | 函数+坐标 | 函数值 | 算子学习 |
| FNO | 场数据 | 场数据 | 傅立叶空间学习 |
| Transformer | 序列数据 | 序列数据 | 时间序列预测 |
学习率调度
请教我"学习率调度"!
预热期后用余弦退火衰减学习率是标准做法。
啊,我明白了!神经网络就是这样的机制。
批归一化与层归一化
请教我"批归一化与层归一化"!
那么说,神经网络做好了,首先就没什么问题吧?
预处理与后处理
接下来是预处理与后处理的讲座。什么内容?
输入的标准化(零均值、单位方差)对学习稳定性是不可或缺的。输出的缩放同样重要。物理量的量级相差很大时(压力:10⁵ Pa、速度:10⁰ m/s),需要分别缩放。
哇,神经网络的讲座,超有意思!请再讲讲。
误差评价与精度验证
听说过"误差评价与精度验证"这个词,但可能还没完全理解…
离散化误差的评价
离散化误差的评价具体是什么意思?
用Richardson外推法估计离散化误差:
这里 $f_h$ 是网格间距 $h$ 的解,$r$ 是网格比,$p$ 是离散化的阶。
GCI(网格收敛指数)
请教我"GCI(网格收敛指数)"!
基于ASME V&V标准的网格收敛性定量评价:
到这里听了一圈,终于明白了为什么离散化误差的评价这么重要!
用公式表示就是这样。
仅看公式还是不太明白…这表示什么呢?
安全系数 $F_s = 1.25$(3水平以上网格比较时)。以 GCI < 5% 为收敛目标。
前辈说"离散化误差的评价一定要好好做",现在明白那是什么意思了。
验证基准问题
请教我"验证基准问题"!
为确保分析结果的信可靠性,推荐与以下基准问题的比较:
| 领域 | 基准 | 参考解 |
|---|---|---|
| 结构 | 块体测试 | 一样应力场的重现 |
| 结构 | Scordelis-Lo屋顶 | 参考位移 |
| 流体 | 盖驱动腔 | Ghia et al. (1982) |
| 热 | 1D解析解 | $T(x) = T_0 + (T_1-T_0)x/L$ |
加速方法
老师,请教我"加速方法"!
哇,DeepONet算子学习真深奥啊…但是得到老师的讲解,总算整理清楚了!
嗯,干得不错!真正的学习就是通过动手实践。如果有不懂的地方,任何时候都可以问我。
DeepONet实现详解——trunk/branch网络的设计与采样战略
在DeepONet实现中重要的是branch网络的输入设计。要对输入函数u(x)在哪些点采样(传感器点的配置)产生的精度直接影响。固定的随机传感器点只能获取函数的局部信息,因此根据问题有时需要先变换为一致网格或傅立叶特征再输入。Lu et al.的原论文表明增加传感器点数精度单调提高,但实际中通常在100~500点左右收敛。
DeepONet算子学习的实务应用
对DeepONet算子学习进行实务应用时的分析流程与最佳实践进行讲解。
老师的讲解容易明白!算子学习实务中的疑惑云散了。
分析流程
从第一步开始请教我!从哪里开始?
1. 问题定义:明确目标变量和设计变量,整理输出的维数和范围
2. 实验计划:制定高效采样计划(拉丁超立方法LHS或Sobol列)
3. 运行CAE模拟:构建参数研究自动化流水线
4. 模型学习:数据预处理→特征选择→学习→交叉验证的迭代循环
5. 预测与最优化:利用构建的模型进行高速设计空间探索与最优解导出
最佳实践
老师,请教我"最佳实践"!
到这里听了一圈,终于明白了为什么数据质量的确保这么重要!
质量管理与文档化
有没有教科书上没有的"现场知识"?
要系统性地文档化分析条件、使用数据、模型参数、验证结果。分析报告中要描明输入条件、假设、结果合理性评价、已知限制。团队知识共享应活用Jupyter Notebook或Confluence等文档平台。
实务工作流
在实务中使用DeepONet算子学习时,最需要注意的是什么?
步骤1: 数据准备
步骤具体是什么意思?
1. 运行高精度模拟(网格已收敛)多个案例
2. 用拉丁超立方采样(LHS)高效覆盖输入参数空间
3. 数据预处理:标准化、删除异常值、特征工程
4. 分割为训练数据(70%)/验证数据(15%)/测试数据(15%)
步骤2: 模型构建
接下来是步骤的讲座。什么内容?
1. 架构选择(根据问题特性)
2. 超参数初始设置(学习率: 1e-3、批规模: 32为目安)
3. 早期停止(Early Stopping)的设置(patience: 50-100轮)
4. 多次学习验证统计稳定性
老师的讲解容易明白!步骤的疑惑云散了。
步骤3: 验证与合理性确认
请教我"步骤"!
1. 对测试数据的预测精度评价(RMSE、R²、最大误差)
2. 物理的整合性确认(保存律、边界条件满足度)
3. 外推测试:学习范围外参数的动作确认
4. 敏感度分析:输入参数的影响度评价
哇,步骤的讲座,超有意思!请再讲讲。
常见失败与对策
请教我"常见失败与对策"!
| 症状 | 原因 | 对策 |
|---|---|---|
| 学习不收敛 | 学习率太高、数据预处理不足 | 学习率改为1/10、数据标准化 |
| 过度拟合(验证误差增加) | 模型过于复杂 | 加入Dropout、数据增量 |
| 外推精度低 | 物理约束不足 | 采用PINN风格方法 |
| 特定区域精度差 | 样本不足 | 用主动学习获取追加样本 |
项目管理与工作流自动化
想粗略掌握全体流程,分步骤教我?
推荐的目录结构
接下来是推荐目录结构的讲座。什么内容?
```
project/
├── cad/ # CAD模型
├── mesh/ # 网格文件
├── setup/ # 分析设置文件
├── results/ # 计算结果
│ ├── case01/
│ ├── case02/
│ └── ...
├── postprocess/ # 后处理脚本·图像
├── report/ # 报告
└── validation/ # 验证数据
```
自动化脚本的活用
接下来是自动化脚本的活用的讲座。什么内容?
将参数研究和网格收敛性确认用Python脚本自动化,大幅提高可重复性和效率。
那么说,推荐目录结构做好了,首先就没什么问题吧?
审查检查表
请教我"审查检查表"!
1. 输入数据:材料常数的单位制、CAD尺寸精度、网格质量指标
2. 边界条件:物理合理性、过约束/约束不足检查
3. 求解器设置:收敛判定基准、时间步长、输出频率
4. 结果验证:力平衡、能量平衡、与理论解的比较
5. 敏感度分析:网格依赖性、边界条件的影响、材料参数的不确定性
也就是说在推荐目录结构那里掉以轻心,后面就会吃亏吧。我会牢记于心!
报告书编制要点
老师,请教我"报告书编制要点"!
质量管理与文档化
在实务中使用DeepONet算子学习时,最需要注意的是什么?
分析质量保证(QA)的要求
请教我"分析质量保证"!
基于ASME V&V 10-2019和NAFEMS QSS的分析质量保证基本要求:
1. 分析计划书:事先文档化目的、适用范围、方法、判定基准
2. 输入数据的管理:版本管理、变更历史的追踪
3. 独立验证:第三方对输入数据和结果的确认
4. 可追溯性:CAD模型→网格→分析条件→结果的全工程可追踪
高效的参数研究
请教我"高效的参数研究"!
为高效评价参数的影响度,推荐活用以下试验计划法(DOE):
结果不确定性的定量化
接下来是结果不确定性定量化的讲座。什么内容?
识别分析结果的不确定性源,进行定量评价:
哇,DeepONet算子学习真深奥啊…但是得到老师的讲解,总算整理清楚了!
嗯,干得不错!真正的学习就是通过动手实践。如果有不懂的地方,任何时候都可以问我。
DeepONet实现设计最优化的加速——翼型解析的应用
翼型(机翼)的CFD解析一个案例要花数小时,这使得形状最优化的反复计算成为瓶颈。用DeepONet可以学习"翼型形状的函数 → 压力·升力系数的函数"这个算子,学习后仅需毫秒级就能得到翼型的输出。斯坦福大学计算机科学系2023年公开的案例中,用NACA系翼型1000个案例学习的DeepONet对未知翼型形状达到95%以上精度,将最优化循环加速了1000倍以上。
DeepONet算子学习的软件比较
对应DeepONet算子学习的主要工具进行比较。
主要平台
接下来是「主要平台」呢!这是什么内容?
| 工具 | 特性 | 对应方法 |
|---|---|---|
| Ansys Twin Builder | 数字孪生用ROM生成 | POD, NN |
| MATLAB/Simulink | 丰富的ML/最优化工具箱 | GP, NN, PCE |
| Altair HyperStudy | DOE·最优化·代理模型整合 | Kriging, RBF |
| modeFRONTIER | 多目标最优化平台 | GP, RSM |
| Dassault SIMULIA | Abaqus连携ML基盘 | ROM, NN |
| Neural Concept Shape | 3D深度学习形状最优化 | CNN, GNN |
选择标准
结局哪个合适,判断标准教我?
综合评价既有CAE工作流的整合性、Python/API脚本扩展性、许可证形态(节点锁定/浮动)、技术支持的质量。同时要确认是否有学术机构专用免费许可。
明白了…工作流的整合看似简单,其实很深奥呢。
主要工具与框架比较
有不少软件吧?各自特性教我!
| 工具 | 开发机构 | 特性 | 许可证 |
|---|---|---|---|
| PyTorch | Meta | 动态计算图,研究用主流 | BSD |
| TensorFlow | 大规模部署优势 | Apache 2.0 | |
| JAX | 自动微分·JIT编译,科学计算向 | Apache 2.0 | |
| NVIDIA Modulus | NVIDIA | PINN专用、GPU优化 | Apache 2.0 |
| DeepXDE | 研究社区 | PINN库、多后端对应 | LGPL |
| Ansys AI/ML | Ansys | 商用CAE整合 | 商用 |
| COMSOL + LiveLink | COMSOL | MATLAB/Python连携 | 商用 |
| SimNet (NVIDIA) | NVIDIA | 大规模物理模拟向 | 商用 |
框架选择指引
接下来是框架选择指引的讲座。什么内容?
啊,我明白了!工具就是这样的机制。
许可证形态与总拥有成本(TCO)
接下来是「许可证形态与总拥有成本(TCO)」呢!这是什么内容?
商用工具的成本结构
商用工具的成本结构具体是什么意思?
| 项目 | 年额目安 | 备注 |
|---|---|---|
| 节点锁定许可 | 100-500万日元 | 固定到1台PC |
| 浮动许可 | 150-800万日元 | 网络内共用 |
| HPC令牌 | 50-300万日元 | 并行核数的从量制 |
| 支持·维护 | 许可的15-25% | 版本升级含 |
| 培训 | 30-80万日元/课程 | 初期导入时必需 |
TCO比较的要点
比较的要点具体是什么意思?
厂商技术支持比较
请教我"厂商技术支持比较"!
导入流程与迁移战略
接下来是「导入流程与迁移战略」呢!这是什么内容?
厂商选定的步骤
请教我"厂商选定的步骤"!
1. 需求定义:明确需要的分析功能、规模、精度要求
2. 候选名单作成:缩小到3-5家
3. 基准评价:各工具用自社的典型问题解析
4. TCO算出:5年间的总拥有成本(许可+HPC+教育+支持)
5. PoC(概念实证):实业务试用期(3-6个月)
6. 最终选定:技术评价+成本+支持+将来性的综合评价
工具迁移时的注意点
请教我"工具迁移时的注意点"!
哇,DeepONet算子学习真深奥啊…但是得到老师的讲解,总算整理清楚了!
嗯,干得不错!真正的学习就是通过动手实践。如果有不懂的地方,任何时候都可以问我。
DeepONet的商用化——NVIDIA Modulus和DeepXDE的实现支持
从研究到产业实装的转变,DeepONet比其他PINN系方法更迅速。从NVIDIA Modulus 22.09开始,DeepONet被正式纳入,可使用GPU优化的实现。DeepXDE库(Lu et al.开发·公开)也本地支持DeepONet,仅需10行左右代码就能实现基本的算子学习。Ansys、西门子都在产品路线图中列入了DeepONet类的神经算子作为代理模型,2025年以后的商用展开受期待。
DeepONet算子学习的先端研究
对DeepONet算子学习的最新研究动向与今后展望进行阐述。
前辈说"演算子学习的最新动向一定要好好做",现在明白那是什么意思了。
最新研究动向
DeepONet算子学习的领域,将来会怎样进化?
近年来,基础模型(Foundation Model)在CAE的应用受到关注。大规模物理模拟数据的预学习模型用少量目标数据微调的方法,数据效率有可能飞跃式提高。另外,用GNN进行网格基的学习和用神经算子进行与分辨率无关的算子学习也在快速发展。
学术展望
最近的潮流怎样?听听令人兴奋的话题吧!
持续关注国际会议(NeurIPS、ICML、WCCM)和学术期刊(CMAME、JCP、IJNME)的发表动向很重要。通过参与产学协作项目,可以尽早吸收最先端的研究成果到实务中。
2024-2026年的研究动向
最近的潮流怎样?听听令人兴奋的话题吧!
基础模型用于科学
基础模型具体是什么意思?
受大规模语言模型(LLM)成功的启发,科学计算向的基础模型(Foundation Model)研究活跃。尝试构建跨越多个物理领域的预学习模型。
神经算子的发展
的发展具体是什么意思?
物理信息的潮流
的潮流具体是什么意思?
哇,大规模语言模型的讲座,超有意思!请再讲讲。
量子计算 × CAE
接下来是量子计算的讲座。什么内容?
量子线性代数求解器(HHL等)对CAE的适用可能性正在研究,但实用化需要量子位数和错误率的大幅改善。
啊,我明白了!大规模语言模型就是这样的机制。
今后5年的技术路线图
听说过"今后5年的技术路线图"这个词,但可能还没完全理解…
2024-2025: 基础技术的成熟
接下来是基础技术的成熟的讲座。什么内容?
2025-2026: 整合与自动化
接下来是整合与自动化的讲座。什么内容?
啊,我明白了!基础技术的成熟就是这样的机制。
2027以后: 范式转变
范式转变具体是什么意思?
哇,基础技术的成熟的讲座,超有意思!请再讲讲。
学术动向与主要国际会议
老师,请教我"学术动向与主要国际会议"!
那么说,计算力学最大的国际会议做好了,首先就没什么问题吧?
标准规范与认证
接下来是「标准规范与认证」呢!这是什么内容?
CAE相关主要规范
请教我"相关主要规范"!
| 规范 | 发行机构 | 概要 |
|---|---|---|
| ASME V&V 10 | ASME | 计算固体力学的V&V指南 |
| ASME V&V 20 | ASME | 计算流体力学的V&V指南 |
| NAFEMS QSS | NAFEMS | 工程模拟的质量基准 |
| ISO 23247 | ISO | 数字孪生框架 |
| DO-178C | RTCA | 航空软件的安全认证 |
认证获取的CAE活用
接下来是认证获取的的讲座。什么内容?
在航空·原子力·医疗设备等规管产业,模拟结果被纳入认证流程的案例增加。美国FDA(食品医药品局)发行了医疗设备认可时受理以模拟为基础的证据的指南。
国际研究计划
国际研究计划具体是什么意思?
哇,DeepONet算子学习真深奥啊…但是得到老师的讲解,总算整理清楚了!
嗯,干得不错!真正的学习就是通过动手实践。如果有不懂的地方,任何时候都可以问我。
DeepONet的最前线——Physics-Informed DeepONet与不确定性定量化
DeepONet的进一步发展是Physics-Informed DeepONet(PI-DeepONet),即使学习数据较少,也通过在损失中加入PDE约束来大幅提高泛化性能。Wang et al. 2022(《SIAM Journal on Scientific Computing》)提案的这个方法,报告说即使仅数十样本的训练数据也比传统DeepONet精度改善10倍以上。进一步,结合Dropout和Deep Ensemble的不确定性定量化(UQ)加DeepONet也出现了,现在可以输出预测信心区间。
DeepONet算子学习的故障处理
对DeepONet算子学习的常见问题与处理方法总结。
1. 模型过度拟合
请教我"模型过度拟合"!
症状:训练误差小但验证误差大。对训练数据的过度适合发生。
处理:增加正则化(L2、Dropout)、数据增量、交叉验证的超参调整。导入早期停止(Early Stopping)。
等等,算子学习时也常见这个吗,所以这种情况下也能用?
2. 预测精度不足
接下来是预测精度不足的讲座。什么内容?
症状:验证数据精度停留在R²<0.9,实用的预测困难。
处理:特征工程重新检查、样本数增加、模型复杂度的阶段性提升、组合方法的导入。
3. 学习不稳定
请教我"学习不稳定"!
症状:损失函数振动·发散,不收敛。
处理:降低学习率或导入调度器、加入批正规化、应用梯度裁剪。
4. 计算资源不足
请教我"计算资源不足"!
症状:GPU内存不足(OOM)错误或学习时间超时。
处理:减少批规模、混合精度学习(FP16)、模型并列化、梯度检查点的导入。
5. 数据相关问题
请教我"数据相关问题"!
症状:学习数据不足、偏差、噪声导致模型性能下降。
处理:数据增量(物理对称性的活用)、通过主动学习的高效数据收集、鲁棒学习方法导入。构建外值检出与删除流水线。