PINN基础理论
概述
老师!今天是PINN基础理论的讲解,对吧?那到底是什么呢?
PINN基础理论的理论基础
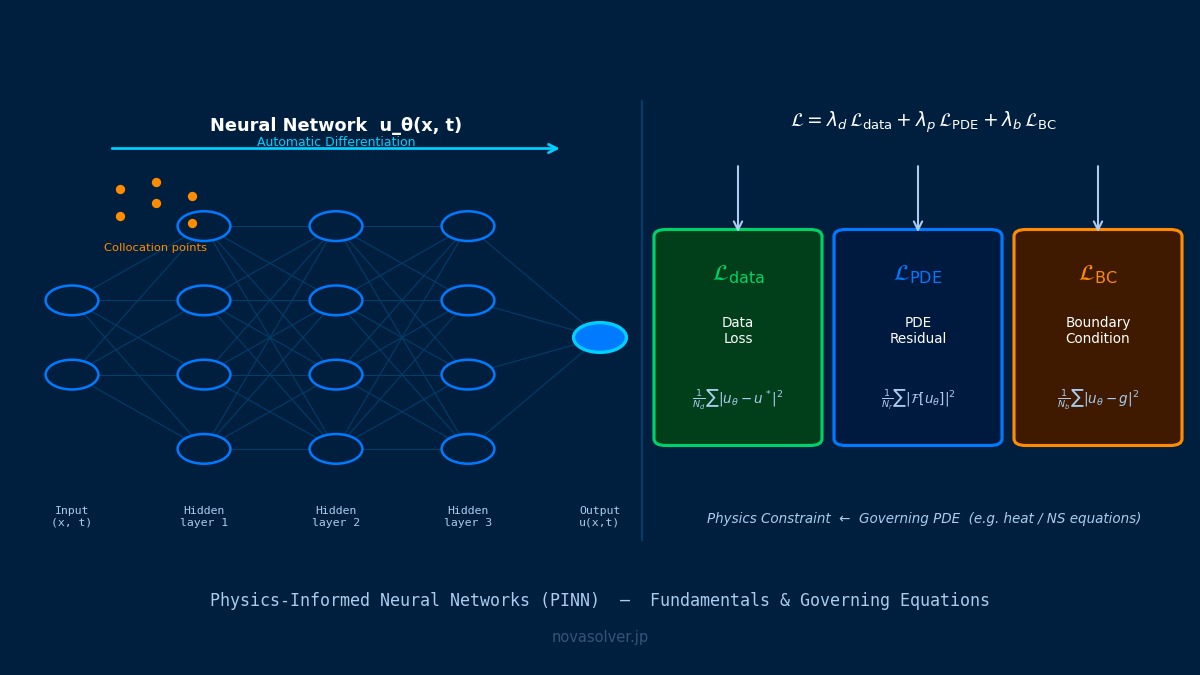
物理信息神经网络(PINN)是将支配方程嵌入神经网络损失函数中,通过学习满足物理定律的解的数据驱动方法。
听到这里,我总算明白了物理信息神经网络的重要性!
支配方程
用公式表示的话就是这样。
嗯,只看公式的话感觉不太明白… 代表什么意思呢?
PDE残差损失:
理论基础
听过「理论基础」这个词,但可能没有真正理解…
PINN基础理论是寻求数据驱动方法和物理基础建模融合的重要技术。在传统CAE分析中计算成本是一个重大瓶颈,但通过引入PINN基础理论可以大幅改善计算效率和预测精度的权衡。该技术的数学基础建立在函数近似理论和统计学习理论之上,泛化性能的保证和收敛性的严格分析是理论研究的重点。特别是当输入维数很高时,「维数诅咒」问题的处理至关重要,通过维数约简和稀疏性活用成为重要的解决方案。
数学表述的详细内容
接下来是「数学表述的详细内容」对吧!这些是什么内容呢?
将机器学习模型应用于CAE时的基本数学框架。
损失函数的构成
损失函数的构成,具体是怎样的呢?
AI×CAE中的损失函数由数据驱动项和物理约束项的加权和构成:
这里 $\mathcal{L}_{\text{data}}$ 是观测数据与的平方误差,$\mathcal{L}_{\text{physics}}$ 是支配方程的残差,$\mathcal{L}_{\text{reg}}$ 是正则化项。权重参数 $\lambda$ 的调整对学习的稳定性和精度有很大影响。
泛化性能和外推问题
关于「泛化性能和外推问题」,请教我!
代理模型的最大课题是学习数据范围之外(外推领域)的预测精度。虽然通过嵌入物理定律可以改善外推性能,但完全保证很困难。
维数诅咒
请教我「维数诅咒」!
当输入参数空间的维数很高时,所需的样本数量会指数增长。通过主动学习(Active Learning)和拉丁超立方体采样(LHS)进行高效的样本配置变得非常重要。
假设条件和适用限制
这个公式万能吗?有什么不能用的情况吗?
啊,原来如此!学习数据充分代表分析对象,就是这样的仕组啊。
无量纲参数和主要尺度
老师,请教我「无量纲参数和主要尺度」!
对支配所分析物理现象的无量纲参数的理解,是选择合适模型和参数设置的基础。
啊,原来如此!对支配所分析物理现象的,就是这样的仕组啊。
维数分析的验证
请教我「维数分析的验证」!
为了估算分析结果的数量级,基于Buckingham Π定理的维数分析很有效。利用代表长度 $L$、代表速度 $U$、代表时间 $T = L/U$,预先估算各物理量的数量级,确认分析结果的合理性。
那么,只要对支配所分析物理现象的理解到位,基本上就没问题了吧?
边界条件的分类和数学特性
听说边界条件如果搞错了,整个分析都会完蛋…
| 种类 | 数学表达式 | 物理意义 | 例 |
|---|---|---|---|
| Dirichlet条件 | $u = u_0$ on $\Gamma_D$ | 变量值的指定 | 固定墙、温度指定 |
| Neumann条件 | $\partial u/\partial n = g$ on $\Gamma_N$ | 梯度(流量)的指定 | 热流束、力 |
| Robin条件 | $\alpha u + \beta \partial u/\partial n = h$ | 变量与梯度的线性组合 | 对流热传递 |
| 周期边界条件 | $u(x) = u(x+L)$ | 空间周期性 | 单位胞元分析 |
边界条件的正确选择直接关系到解的唯一性和物理合理性。边界条件不足会导致不适定问题,过多的边界条件会产生矛盾。
哇,PINN基础理论的深度真是超乎想象… 不过有老师的讲解,总算整理清楚了!
嗯,进度不错!最重要的是要把它付诸实践,动手做一做。有不明白的地方随时问我。
PINN为什么「懂物理」——损失函数的秘密
Raissi et al. 2019年发表PINN论文时,很多研究人员惊讶地说「就是把偏微分方程放在损失函数里?」。实际上就这样,神经网络就会学会在遵守偏微分方程「文法」的同时寻找解。与传统有限元法先切网格再离散方程不同,PINN在连续空间中直接学习满足微分方程的函数,这种思想转换很有意思。
PINN基础理论的数值计算方法
下面讲解实现PINN基础理论时的数值方法和算法。
哦,基础理论的实现讲解,超级有意思!请继续讲!
离散化和计算步骤
这个方程,计算机实际上怎么求解啊?
作为数据的预处理,输入特征量的标准化非常重要。CAE数据的物理量之间数量级差异很大,需要根据情况合理选择Min-Max正规化或Z-score正规化。学习算法的选择应根据数据量、维数和非线性程度来决定。
实现上的注意事项
在实务中使用PINN基础理论时,最需要注意什么?
一般采用Python生态系统(scikit-learn、PyTorch、TensorFlow)进行实现。通过GPU并行化加快学习,超参数自动调优,交叉验证防止过学习是实现的关键。大规模CAE数据的高效I/O处理推荐采用HDF5格式。
验证方法
老师,请教我「验证方法」!
应该根据目的区分使用k折交叉验证、留一法、留出法,用决定系数R²、RMSE、MAE、最大误差等从多个角度评估预测性能。
前辈说「交叉验证一定要好好做」,现在明白是什么意思了。
代码质量和可重现性
在实务中使用PINN基础理论时,最需要注意什么?
通过版本管理(Git)、自动测试(pytest)、CI/CD流水线的导入来确保代码质量和实验可重现性。严格固定依赖库的版本(requirements.txt),使计算环境的重构变得容易。固定随机数种子来确保结果可重现是重要的实现习惯。
啊,原来如此!版本管理就是这样的仕组啊。
实现算法的详细内容
想更深入地了解计算幕后发生了什么!
神经网络架构
接下来是神经网络架构的讲解。内容是什么?
CAE应用中使用的主要架构:
| 架构 | 输入 | 输出 | 应用场景 |
|---|---|---|---|
| 全连接NN (MLP) | 参数向量 | 标量/向量 | 代理模型 |
| CNN | 图像/场数据 | 图像/场数据 | 基于图像的预测 |
| GNN | 图(网格) | 节点值 | 基于网格的预测 |
| DeepONet | 函数 + 坐标 | 函数值 | 算子学习 |
| FNO | 场数据 | 场数据 | Fourier空间学习 |
| Transformer | 序列数据 | 序列数据 | 时间序列预测 |
学习率调度
请教我「学习率调度」!
预热期后用余弦退火衰减学习率是标准做法。
啊,原来如此!神经网络就是这样的仕组啊。
批量正规化和层正规化
请教我「批量正规化和层正规化」!
那么,只要神经网络理解到位,基本上就没问题了吧?
预处理和后处理
接下来是预处理和后处理的讲解。内容是什么?
输入的标准化(零均值、单位方差)对学习稳定性不可或缺。输出的缩放同样重要。当物理量数量级差异很大时(压力:10⁵ Pa、速度:10⁰ m/s),需要单独缩放。
哦,神经网络的讲解,超级有意思!请继续讲!
误差评估和精度验证
听过「误差评估和精度验证」,但可能没有真正理解…
离散化误差的评估
离散化误差的评估,具体是怎样的呢?
采用Richardson外推法进行离散化误差的估计:
这里 $f_h$ 是网格宽度 $h$ 处的解,$r$ 是网格比,$p$ 是离散化的阶数。
GCI(Grid Convergence Index)
请教我「GCI」!
基于ASME V&V 20-2009的网格收敛性定量评估:
听到这里,我总算明白了离散化误差的评估的重要性!
用公式表示的话就是这样。
嗯,只看公式的话感觉不太明白… 代表什么意思呢?
安全系数 $F_s = 1.25$(网格比较3水准以上时)。GCI < 5% 作为收敛目标。
前辈说「离散化误差的评估一定要好好做」,现在明白是什么意思了。
验证基准问题
请教我「验证基准问题」!
为了保证分析结果的可信性,推荐与以下基准问题进行比较:
| 领域 | 基准 | 参考解 |
|---|---|---|
| 结构 | 单元补丁测试 | 均匀应力场的重现 |
| 结构 | Scordelis-Lo屋顶 | 参考位移 |
| 流体 | 盖驱动腔 | Ghia et al. (1982) |
| 热 | 1D分析解 | $T(x) = T_0 + (T_1-T_0)x/L$ |
加速方法
老师,请教我「加速方法」!
哇,PINN基础理论的深度真是超乎想象… 不过有老师的讲解,总算整理清楚了!
嗯,进度不错!最重要的是要把它付诸实践,动手做一做。有不明白的地方随时问我。
自动微分让PINN成为现实——PyTorch和TensorFlow的恩惠
PINN实现中最「令人感激」的是自动微分(autograd)。当想在损失函数中使用偏微分算子时,无需手动差分近似,PyTorch的 torch.autograd.grad() 一句就能得到精确的偏微分。2015年之前这种机制还不完善,PINN实现成本非常高。深度学习框架的进步推动了PINN研究的突破,这一事实虽然鲜为人知,但非常重要。
PINN基础理论的实际应用
讲解将PINN基础理论在实务中活用的分析流程和最佳实践。
分析流程
从第一步开始教我!从哪里着手比较好?
1. 问题定义: 明确目标变量和设计变量,整理输入输出的维数和范围
2. 实验计划: 用拉丁超立方体法(LHS)或Sobol序列制定高效的采样计划
3. CAE仿真执行: 构建参数研究的自动化流水线
4. 模型学习: 数据预处理→特征选择→学习→交叉验证的迭代循环
5. 预测和优化: 用构建的模型进行高速设计空间探索和最优解导出
最佳实践
老师,请教我「最佳实践」!
听到这里,我总算明白了数据质量的确保的重要性!
质量管理和文档化
教科书以外,有什么「实务的智慧」吗?
系统地记录分析条件、使用数据、模型参数、验证结果。分析报告中应注明输入条件、假设条件、结果的妥当性评估、已知限制事项。推荐采用Jupyter Notebook或Confluence等文档基础进行团队知识共享。
实际工作流程
在实务中使用PINN基础理论时,最需要注意什么?
步骤1: 数据准备
步骤,具体是怎样的呢?
1. 运行高精度仿真(网格收敛完成)的多个工况
2. 用拉丁超立方体采样(LHS)高效地覆盖输入参数空间
3. 数据的预处理:标准化、异常值去除、特征工程
4. 分割为训练数据(70%)/ 验证数据(15%)/ 测试数据(15%)
步骤2: 模型构建
接下来是步骤的讲解。内容是什么?
1. 选择架构(根据问题特性)
2. 超参数的初期设置(学习率:1e-3、批量大小:32为目安)
3. 设置早期停止(Early Stopping)(patience:50-100历元)
4. 多次学习确认统计稳定性
老师的讲解好好理解!步骤的疑惑晴朗了。
步骤3: 验证和妥当性确认
请教我「步骤」!
1. 对测试数据的预测精度评估(RMSE、R²、最大误差)
2. 物理整合性确认(守恒定律、边界条件的满足度)
3. 外推测试:学习范围外的参数行为确认
4. 敏感性分析:输入参数的影响度评估
哦,步骤的讲解,超级有意思!请继续讲!
常见的失败和对策
请教我「常见的失败和对策」!
| 症状 | 原因 | 对策 |
|---|---|---|
| 学习不收敛 | 学习率过高、数据预处理不足 | 学习率减半、数据标准化 |
| 过学习(验证误差上升) | 模型过于复杂 | 添加Dropout、数据增强 |
| 外推精度低 | 物理约束不足 | 导入PINN类型方法 |
| 特定区域精度差 | 样本不足 | 用主动学习获取追加样本 |
项目管理和工作流自动化
想大概把握全体流程,能按步骤讲解吗?
目录结构的推荐
接下来是目录结构的推荐的讲解。内容是什么?
```
project/
├── cad/ # CAD模型
├── mesh/ # 网格文件
├── setup/ # 分析设置文件
├── results/ # 计算结果
│ ├── case01/
│ ├── case02/
│ └── ...
├── postprocess/ # 后处理脚本、图像
├── report/ # 报告
└── validation/ # 验证数据
```
自动化脚本的活用
接下来是自动化脚本的活用的讲解。内容是什么?
参数研究和网格收敛性验证可通过Python脚本自动化,大幅提高可重现性和效率。
那么,只要目录结构的推荐理解到位,基本上就没问题了吧?
审查检查清单
请教我「审查检查清单」!
1. 输入数据: 材料常数的单位系统、CAD精度、网格品质指数
2. 边界条件: 物理妥当性、过度约束/约束不足检查
3. 求解器设置: 收敛判定基准、时间步、输出频度
4. 结果验证: 力平衡、能量守恒、理论解的比较
5. 敏感性分析: 网格依赖性、边界条件的影响、材料参数的不确定性
也就是说目录结构的推荐地方偷懒的话,后来吃苦头,吸取教训!
报告编制的要点
老师,请教我「报告编制的要点」!
质量管理和文档化
在实务中使用PINN基础理论时,最需要注意什么?
分析质量保证(QA)的要求
请教我「分析质量保证」!
ASME V&V 10-2019和NAFEMS QSS中的分析质量保证的基本要求:
1. 分析计划书: 事先以文档形式明确目的、适用范围、方法、判定基准
2. 输入数据的管理: 版本管理、变更历史的追踪
3. 独立验证: 第三者对输入数据和结果的确认
4. 可追踪性: CAD模型→网格→分析条件→结果的全工序可追踪
高效的参数研究
请教我「高效的参数研究」!
为了高效评估参数的影响度,推荐采用以下实验计划法(DOE):
结果的不确定性定量化
接下来是结果的不确定性定量化的讲解。内容是什么?
要识别分析结果的不确定性源并进行定量评估:
哇,PINN基础理论的深度真是超乎想象… 不过有老师的讲解,总算整理清楚了!
嗯,进度不错!最重要的是要把它付诸实践,动手做一做。有不明白的地方随时问我。
PINN实现的「常见坑」——学习不收敛的原因Top 3
初次实现PINN的工程师一定会遇上「损失不下降」的问题。原因的Top 3是,①边界条件与支配方程损失的权衡不好,②采样点在域内偏斜,③学习率太高导致参数发散。即使Raissi的原始实现有时也需手动调整权重。实务中「Adam→L-BFGS的两阶段学习」正逐渐成为标准。
PINN基础理论的软件比较
比较支持PINN基础理论的主要工具。
主要平台
接下来是「主要平台」对吧!这些是什么内容呢?
| 工具 | 特点 | 对应方法 |
|---|---|---|
| Ansys Twin Builder | 数字孪生的ROM生成 | POD、NN |
| MATLAB/Simulink | 丰富的ML/优化工具箱 | GP、NN、PCE |
| Altair HyperStudy | DOE·优化·代理统合 | Kriging、RBF |
| modeFRONTIER | 多目标优化平台 | GP、RSM |
| Dassault SIMULIA | Abaqus连携ML基盘 | ROM、NN |
| Neural Concept Shape | 3D深度学习形状最适化 | CNN、GNN |
选择标准
最终选什么,判断标准能教我吗?
评估既有CAE工作流的统合性、Python/API脚本扩展性、许可形式(节点锁定/浮动)、技术支持的质量。还应确认是否有学术机构免费许可。
原来…工作流的统合虽然看似简单,但深度真的超乎想象…
主要工具和框架比较
那么多软件啊?各自的特色教教我!
| 工具 | 开发商 | 特点 | 许可 |
|---|---|---|---|
| PyTorch | Meta | 动态计算图、研究用主流 | BSD |
| TensorFlow | 大规模部署强项 | Apache 2.0 | |
| JAX | 自动微分·JIT编译、科学计算向 | Apache 2.0 | |
| NVIDIA Modulus | NVIDIA | PINN特化、GPU最适化 | Apache 2.0 |
| DeepXDE | 研究社区 | PINN库、多后端对应 | LGPL |
| Ansys AI/ML | Ansys | 商用CAE统合 | 商用 |
| COMSOL + LiveLink | COMSOL | MATLAB/Python连携 | 商用 |
| SimNet (NVIDIA) | NVIDIA | 大规模物理仿真向 | 商用 |
框架选择的指针
接下来是框架选择的指针的讲解。内容是什么?
啊,原来如此!工具就是这样的仕组啊。
许可形式和总所有成本(TCO)
接下来是「许可形式和总所有成本(TCO)」对吧!这些是什么内容呢?
商用工具的成本结构
商用工具的成本结构,具体是怎样的呢?
| 项目 | 年额目安 | 备考 |
|---|---|---|
| 节点锁定许可 | 100-500万円 | 固定到1台PC |
| 浮动许可 | 150-800万円 | 网络内共享 |
| HPC令牌 | 50-300万円 | 并行核数应有的往返式 |
| 支持·维护 | 许可的15-25% | 含版本升级 |
| 培训 | 30-80万円/课程 | 初期导入时必需 |
TCO比较的要点
比较的要点,具体是怎样的呢?
供应商的技术支持比较
请教我「供应商的技术支持比较」!
导入流程和迁移策略
接下来是「导入流程和迁移策略」对吧!这些是什么内容呢?
供应商选择的步骤
请教我「供应商选择的步骤」!
1. 要求定义: 明确必要的分析功能、规模、精度要求
2. 候选清单: 缩小到3-5家
3. 基准评估: 各工具用自社典型问题求解
4. TCO计算: 5年总所有成本(许可+HPC+教育+支持)
5. PoC(概念实证): 实业务试用期(3-6个月)
6. 最终选定: 技术评估+成本+支持+将来性的综合评估
工具迁移时的注意事项
请教我「工具迁移时的注意事项」!
哇,PINN基础理论的深度真是超乎想象… 不过有老师的讲解,总算整理清楚了!
嗯,进度不错!最重要的是要把它付诸实践,动手做一做。有不明白的地方随时问我。
PINN商用工具的现状——NVIDIA Modulus正在成为业界标准的理由
2022年NVIDIA发布Modulus(前称SimNet)之后,作为首个产业级PINN框架引起关注。具备GPU最适化、分布式学习、可视化流水线,Boeing和Siemens等公司也发表了采用事例。另一方面,学术界绝对主流是DeepXDE(Lu等),截至2024年末论文引用数超过3000。「先试试看选DeepXDE,产业展开选Modulus」这样的分工已成惯例。
PINN基础理论的先进研究
讲述PINN基础理论中最新的研究动向和今后的展望。
等等,基础理论的最新研究动向,是说即便这样的情况下也能用吗?
最新研究动向
PINN基础理论的领域,今后会怎么发展?谈点让人兴奋的话题吧!
近来,基础模型(Foundation Model)的CAE应用引起关注。用大规模物理仿真数据预训练的模型,通过少量目标数据的微调能大幅提高数据效率。同时,基于GNN的网格学习和Neural Operator的分辨率无关算子学习也急速发展。
学术展望
最近的流行趋势怎么样?说点让人兴奋的话吧!
需要持续关注国际会议(NeurIPS、ICML、WCCM)和学术期刊(CMAME、JCP、IJNME)的发表动向。通过参与产学合作项目,可以尽早获得最先进的研究成果。
2024-2026年的研究动向
最近的流行趋势怎么样?说点让人兴奋的话吧!
基础模型在科学中的应用
Foundation Models,具体是怎样的呢?
大型语言模型(LLM)成功的启发下,科学计算用基础模型(Foundation Model)的研究活跃化。尝试构建跨多个物理领域的预训练模型。
Neural Operator 的发展
的发展,具体是怎样的呢?
Physics-Informed 的潮流
的潮流,具体是怎样的呢?
哦,基础模型的讲解,超级有意思!请继续讲!
量子计算 × CAE
接下来是量子计算的讲解。内容是什么?
量子线性代数求解器(HHL等)的CAE应用可能性正在研究,但实用化需要量子比特数和误差率的大幅改善。
啊,原来如此!基础模型就是这样的仕组啊。
今后5年的技术路线图
「今后5年的技术路线图」听过,但可能没有真正理解…
2024-2025: 基础技术的成熟
接下来是基础技术的成熟的讲解。内容是什么?
2025-2026: 统合与自动化
接下来是统合与自动化的讲解。内容是什么?
啊,原来如此!基础技术的成熟就是这样的仕组啊。
2027以后: 范式转移
范式转移,具体是怎样的呢?