DeepONet Operator Learning
Overview
Professor! Today let us talk about DeepONet operator learning, right? What is it about?
DeepONet Operator Learning: Theoretical Foundations
DeepONet is an architecture that learns function-to-function mappings (operators). It encodes the input function with the Branch Net, processes the output location with the Trunk Net, and combines them.
I see. So, if it can perform a function-to-function mapping, is it basically okay for starters?
Governing Equations
Expressing this mathematically looks like this.
Hmm, just the equation doesn't really click for me... What does it represent?
Loss function:
So, if you cut corners on the loss function part, you'll pay for it later, right? I'll keep that in mind!
Theoretical Foundation
I've heard of "theoretical foundation," but I might not fully understand it...
DeepONet operator learning is an important method aiming to fuse data-driven approaches and physics-based modeling. While computational cost is a major bottleneck in conventional CAE analysis, introducing DeepONet operator learning can significantly improve the trade-off between computational efficiency and prediction accuracy. The mathematical foundation of this method is based on function approximation theory and statistical learning theory, with theoretical research topics including guarantees of generalization performance and rigorous analysis of convergence. Particularly, dealing with the "curse of dimensionality" when the input dimension is high is a key practical challenge, and approaches like dimensionality reduction and leveraging sparsity are important.
Details of Mathematical Formulation
Next is "Details of Mathematical Formulation"! What kind of content is this?
It shows the basic mathematical framework for applying machine learning models to CAE.
Loss Function Composition
What does "loss function composition" mean specifically?
In AI×CAE, the loss function is composed as a weighted sum of a data-driven term and a physics constraint term:
Here, $\mathcal{L}_{\text{data}}$ is the squared error with observed data, $\mathcal{L}_{\text{physics}}$ is the residual of the governing equations, and $\mathcal{L}_{\text{reg}}$ is a regularization term. Adjusting the weight parameters $\lambda$ greatly affects learning stability and accuracy.
Generalization Performance and Extrapolation Problem
Please tell me about "Generalization Performance and the Extrapolation Problem"!
The biggest challenge for surrogate models is prediction accuracy outside the range of training data (extrapolation region). Incorporating physical laws can improve extrapolation performance, but complete guarantees are difficult.
Curse of Dimensionality
Please tell me about the "Curse of Dimensionality"!
When the dimension of the input parameter space is high, the required number of samples increases exponentially. Efficient sample placement through Active Learning or Latin Hypercube Sampling (LHS) is super important.
Assumptions and Applicability Limits
Isn't this formula universal? When can't it be used?
- The training data sufficiently represents the physics of the analysis target.
- The relationship between input parameters and output is smooth (if discontinuities exist, domain decomposition is needed).
- Reducing computational cost is the main purpose; conventional solvers should be used in conjunction for final verification requiring high accuracy.
- If the quality of training data (mesh-converged, V&V completed) is insufficient, model reliability decreases.
Ah, I see! So that's how the training data being the analysis target works.
Dimensionless Parameters and Dominant Scales
Professor, please tell me about "Dimensionless Parameters and Dominant Scales"!
Understanding the dimensionless parameters governing the physical phenomenon being analyzed is the foundation for appropriate model selection and parameter setting.
- Péclet Number Pe: Relative importance of convection vs. diffusion. Pe >> 1 indicates convection-dominated (stabilization methods required).
- Reynolds Number Re: Ratio of inertial forces to viscous forces. A fundamental parameter for fluid problems.
- Biot Number Bi: Ratio of internal conduction to surface convection. For Bi < 0.1, the lumped capacitance method is applicable.
- Courant Number CFL: Indicator of numerical stability. For explicit methods, CFL ≤ 1 is required.
Ah, I see! So that's how the physical phenomenon being analyzed works.
Verification via Dimensional Analysis
Please tell me about "Verification via Dimensional Analysis"!
For order-of-magnitude estimation of analysis results, dimensional analysis based on Buckingham's Π theorem is effective. Using characteristic length $L$, characteristic velocity $U$, and characteristic time $T = L/U$, the order of each physical quantity is estimated beforehand to confirm the validity of the analysis results.
I see. So, if you can handle the physical phenomenon being analyzed, is it basically okay for starters?
Classification of Boundary Conditions and Mathematical Characteristics
I've heard that if you get the boundary conditions wrong, everything fails...
| Type | Mathematical Expression | Physical Meaning | Example |
|---|---|---|---|
| Dirichlet Condition | $u = u_0$ on $\Gamma_D$ | Specification of variable value | Fixed wall, specified temperature |
| Neumann Condition | $\partial u/\partial n = g$ on $\Gamma_N$ | Specification of gradient (flux) | Heat flux, force |
| Robin Condition | $\alpha u + \beta \partial u/\partial n = h$ | Linear combination of variable and gradient | Convective heat transfer |
| Periodic Boundary Condition | $u(x) = u(x+L)$ | Spatial periodicity | Unit cell analysis |
Choosing appropriate boundary conditions is directly linked to solution uniqueness and physical validity. Insufficient boundary conditions lead to ill-posed problems, while excessive ones cause contradictions.
Wow, DeepONet operator learning is really deep... But thanks to your explanation, I've managed to organize my thoughts a lot!
Yeah, you're doing great! Actually getting your hands dirty is the best way to learn. If you have any questions, feel free to ask anytime.
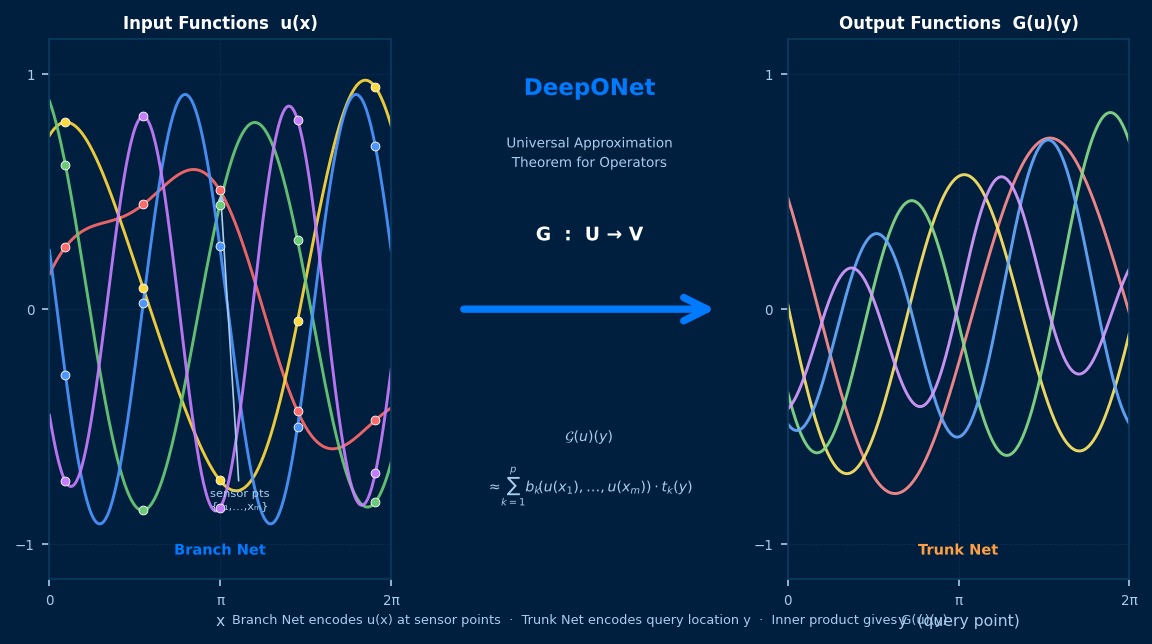
What it Means for DeepONet to "Learn an Operator"—From Chen's Universal Approximation Theorem
In 1995, Chen and Chen proved the "Universal Approximation Theorem for Operators," showing that neural networks can approximate nonlinear operators to arbitrary accuracy. DeepONet (Lu et al. 2021, published in Nature Machine Intelligence) implemented this theorem using deep learning. The architecture, where the trunk network learns basis functions for the output space and the branch network predicts coefficients for the input function, is the mechanism for learning "function→function" mappings. The revolutionary aspect was that the solution operator could be evaluated in a single forward pass, without repeatedly solving PDEs.
Computational Methods for DeepONet Operator Learning
Explains numerical methods and algorithms for implementing DeepONet operator learning.
Discretization and Computational Procedure
How do you actually solve this equation on a computer?
As data preprocessing, normalization/standardization of input features is important. Since CAE data have vastly different scales for each physical quantity, it's necessary to appropriately choose methods like Min-Max normalization or Z-score normalization. In selecting learning algorithms, appropriate methods should be chosen based on data volume, dimensionality, and degree of nonlinearity.
Implementation Considerations
What's the most important thing to be careful about when using DeepONet operator learning in practice?
Implementation using the Python ecosystem (scikit-learn, PyTorch, TensorFlow) is common. Keys to implementation are learning acceleration via GPU parallelization, automatic hyperparameter tuning, and preventing overfitting via cross-validation. Using the HDF5 format is recommended for efficient I/O processing of large-scale CAE data.
Verification Methods
Professor, please tell me about "Verification Methods"!
It's important to use k-fold cross-validation, Leave-One-Out method, and holdout method appropriately for the purpose, and to evaluate prediction performance comprehensively using coefficient of determination R², RMSE, MAE, and maximum error.
Now I understand what my senior meant when they said, "At least do cross-validation properly."
Code Quality and Reproducibility
What's the most important thing to be careful about when using DeepONet operator learning in practice?
Ensure code quality and experiment reproducibility by introducing version control (Git), automated testing (pytest), and CI/CD pipelines. Strictly enforce dependency version pinning (requirements.txt) to make rebuilding the computational environment easy. Fixing random seeds to ensure result reproducibility is also an important implementation practice.
Ah, I see! So that's how version control works.
Details of Implementation Algorithms
I want to know a bit more about what's happening behind the scenes of the computation!
Neural Network Architecture
Next is the topic of neural network architecture. What kind of content is it?