データ同化手法
データ同化手法の理論基礎
概要
先生、「データ同化」って天気予報で聞いたことがありますけど、CAEでも使うんですか?
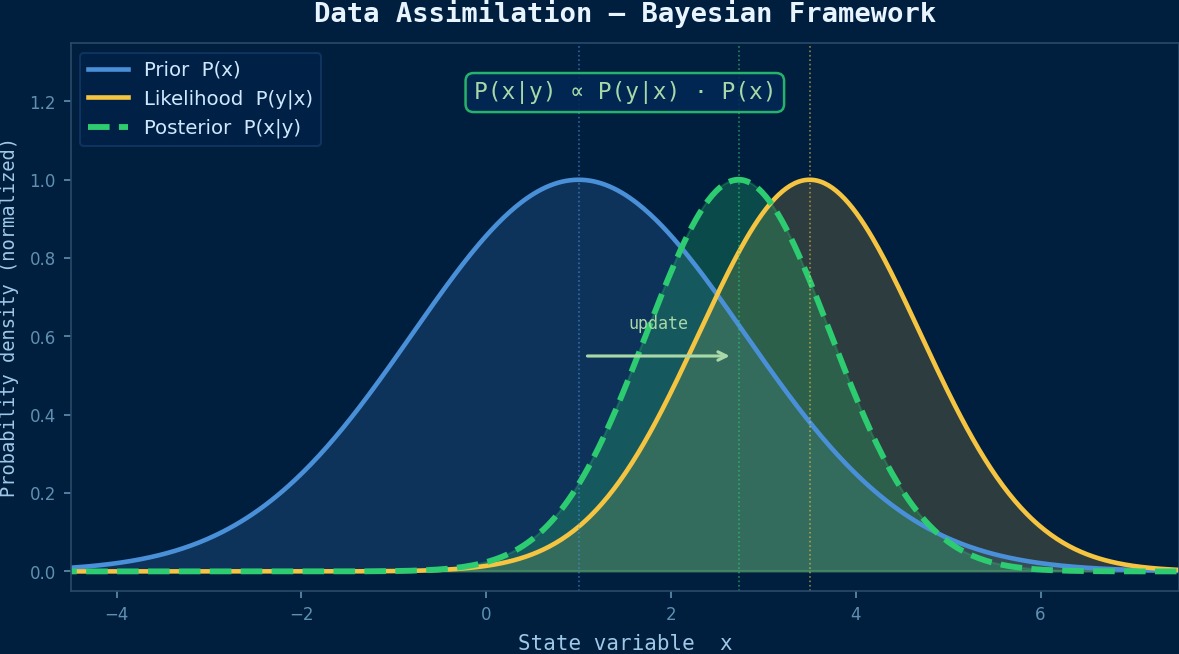
まさにその通り。データ同化とは、シミュレーション予測と観測データを統計的に最適融合し、状態推定の精度を向上させる手法だ。天気予報では大気モデルと観測点データを融合して予報精度を上げているが、CAEでもセンサデータとFEMシミュレーションを組み合わせて、構造物の現在の状態をリアルタイムに推定できる。
センサだけじゃダメなんですか?
センサは配置した場所の情報しか得られない。橋梁に10個のひずみゲージを貼っても、数万点の節点情報は得られないだろう。データ同化を使えば、限られたセンサ情報をシミュレーションモデルで空間的に補間・外挿して、構造全体の状態を推定できるんだ。
支配方程式
数学的にはどう定式化されるんですか?
カルマンフィルタの枠組みで説明しよう。状態ベクトル $\mathbf{x}$ の予測値(シミュレーション)と観測値を融合して、解析値(最適推定値)を得る。
ここで $\mathbf{x}^f$ は予報値、$\mathbf{y}^o$ は観測値、$\mathbf{H}$ は状態空間から観測空間への変換演算子だ。カルマンゲイン $\mathbf{K}$ が予測と観測の重み配分を決める。
$\mathbf{P}^f$ と $\mathbf{R}$ は何ですか?
$\mathbf{P}^f$ は予測の誤差共分散行列(シミュレーションの不確かさ)、$\mathbf{R}$ は観測の誤差共分散行列(センサの不確かさ)だ。シミュレーションが信頼できるならカルマンゲインは小さくなり観測補正が弱くなる。逆にセンサの精度が高ければ観測側を重視する。この自動的な重み調整がデータ同化の本質だ。
主要手法の分類
カルマンフィルタ以外にもあるんですか?
大きく分けて2つの流派がある。
- 逐次法: アンサンブルカルマンフィルタ(EnKF)。予測の不確かさをモンテカルロ的にアンサンブルメンバーで表現する。非線形問題に対応できるが、アンサンブルサイズが小さいとサンプリング誤差が問題になる
- 変分法: 3D-Var/4D-Var。コスト関数 $J(\mathbf{x}) = (\mathbf{x}-\mathbf{x}^f)^T\mathbf{B}^{-1}(\mathbf{x}-\mathbf{x}^f) + (\mathbf{y}^o-\mathbf{H}\mathbf{x})^T\mathbf{R}^{-1}(\mathbf{y}^o-\mathbf{H}\mathbf{x})$ を最小化する。4D-Varは時間方向も考慮する
CAEではどちらが使われますか?
構造ヘルスモニタリングではEnKFが多い。FEMソルバーを$N$回(アンサンブルサイズ分)走らせて予測のばらつきを推定し、実測値で修正する。FEMが重い場合は縮約基底モデル(ROM)と組み合わせて計算コストを下げる工夫が必要だ。
カルマンフィルタ——気象予測から構造解析へ渡った50年
データ同化の理論的中心にあるのがカルマンフィルタ(1960年提案)だ。もともとアポロ計画の軌道推定のために開発されたこのアルゴリズムは、今や気象数値予報の要となっている。日本の気象庁も4次元変分法(4D-Var)と組み合わせた独自システムで台風進路予測に活用している。これをCAEの構造解析に応用した研究が2010年代に急増した。例えばMITの研究グループは、実験中の材料試験片に貼ったDICカメラの全視野変位データをアンサンブルカルマンフィルタで逐次同化し、ヤング率や降伏応力を「計測しながら同定」する手法を発表した。「解析が実験を補い、実験が解析を修正する」というループこそがデータ同化の本質だ。
データ同化手法の数値計算手法
EnKFの実装手順
EnKFを実装するとき、具体的にどんなステップを踏むんですか?
構造解析のデータ同化を例に説明しよう。
1. 初期アンサンブル生成: 材料パラメータや荷重条件に不確かさを与えた$N$個のFEMモデルを作る($N$=50〜200が目安)
2. 予測ステップ: 各アンサンブルメンバーでFEM解析を実行し、状態ベクトル(変位、応力等)を得る
3. 観測演算子の適用: 各メンバーの状態から「もしセンサがあったらどう見えるか」を計算する
4. 更新ステップ: カルマンゲインを計算し、実際の観測値との差でアンサンブル全体を修正する
5. 統計量の算出: 修正後のアンサンブルの平均が最適推定値、分散が推定の不確かさになる
FEMを50回も200回も回すんですか? めちゃくちゃ計算コスト高くないですか?
だからこそ計算コスト削減が重要テーマなんだ。対策は3つある。
- ROM化: POD(固有直交分解)でFEMモデルを低次元化し、$N$回の計算を高速化する
- 局所化: カルマンゲインの空間的な影響範囲を制限して、不要な遠方相関を切る
- インフレーション: アンサンブルの分散が小さくなりすぎるのを防ぐために共分散を膨張させる
変分法の実装
変分法のほうはどうやって実装するんですか?
4D-VarではFEMソルバーの随伴方程式(adjoint)が必要になる。コスト関数の勾配を随伴法で効率的に計算し、準ニュートン法(L-BFGSなど)で最適化する。随伴ソルバーの実装は大変だが、感度解析や逆問題にも使えるので投資価値はある。ただ、多くの商用FEMソルバーは随伴機能を持っていないので、自動微分(AD)ツールとの連携が現実的だ。
CAEとの統合パイプライン
既存のCAEワークフローにどう組み込むんですか?
Python上で統合するのが一般的だ。FEMソルバーのバッチ実行スクリプト、EnKFのフィルタリングロジック、センサデータの取得・前処理をPythonで制御する。filterPyやDANEXTなどのオープンソースのデータ同化ライブラリが参考になる。
| コンポーネント | 役割 | ツール例 |
|---|---|---|
| FEMソルバー | 予測計算 | CalculiX, Code_Aster, Abaqus |
| DA フレームワーク | フィルタリング | filterPy, DAPPER, OpenDA |
| ROM生成 | 計算コスト削減 | pyMOR, RBniCS |
| 可視化 | 結果の確認 | ParaView, matplotlib |
リアルタイム処理もできるんですか?
ROM化すれば数秒以内のフィルタリングが可能だ。ただし、ROMの精度がフルモデルに対して十分かどうかの事前検証が不可欠だ。
アンサンブルカルマンフィルタ(EnKF)——モンテカルロで不確かさを扱う
拡張カルマンフィルタ(EKF)は線形近似が前提のため、非線形が強いCAE問題では精度が出ない。そこで登場したのがアンサンブルカルマンフィルタ(EnKF)だ。初期状態の確率分布から数十〜数百個の「アンサンブルメンバー」(サンプル状態)を生成し、各メンバーを物理シミュレーションで時間発展させながら観測データで逐次修正する。実装のポイントはアンサンブルサイズの選択:サイズが小さいと「サンプリングエラー」が大きくなり、大きすぎると計算コストが爆発する。流体解析での実用例では自由度数×アンサンブルサイズがメモリ上限を超えることも多く、局所化(localization)技術で空間的な相関範囲を制限するのが標準的な対処法だ。
データ同化手法の実務適用
実務への適用手順
実際にデータ同化をプロジェクトで使うときの手順を教えてください。
まず対象を選定する。データ同化が有効なのは「シミュレーションモデルは持っているが、パラメータの不確かさがあり、限られたセンサデータで補正したい」場合だ。
1. FEMモデルの構築: まず通常通りFEMモデルを作り、既知の荷重条件でV&Vを実施する
2. 不確かさの同定: 材料定数の公差、荷重の変動範囲、境界条件の不確かさを定量化する
3. センサ計画: どこに何個のセンサを配置するかを最適化する。情報量行列の最大化が指標になる
4. DA手法の選択と実装: EnKFか変分法かを計算コストと精度要求で判断する
5. 双子実験: まずシミュレーションデータで「擬似観測」を生成してDAの性能を検証する
6. 実データでの適用: 双子実験で問題なければ実センサデータに切り替える
双子実験って何ですか?
真の状態を知っている状況でDAの性能を試すテストだ。あるパラメータセットでFEMを実行して「真の解」とし、その結果にノイズを加えて擬似観測を作る。DAで推定した値が真の解にどれだけ近づくかで手法の妥当性を確認する。実データに行く前に必ずやるべきステップだ。
ベストプラクティス
成功のコツは何ですか?
適用事例
どんな分野で使われているんですか?
風力発電タービン疲労監視——データ同化の現場導入事例
デンマークの大手風力発電メーカーVestasは、洋上風力タービンのブレード疲労解析にデータ同化を本格導入している。タービン根本に設置した加速度センサーと歪みゲージから得られるリアルタイムデータを、FEMシミュレーションに逐次同化することで、実際の運転条件下での疲労損傷蓄積を高精度で推定する。従来は設計時の平均的な風況を想定した保守的な計算だったが、データ同化によって個々のタービンの実使用状況に応じたカスタム寿命予測が可能になった。結果として計画外停止を40%削減し、予防保全コストを大幅に圧縮できたという。導入の苦労はセンサーキャリブレーションの継続管理で、潮風と振動による経年劣化への対処が実務上の最大のボトルネックだったそうだ。
データ同化手法のソフトウェア比較
ツールとフレームワーク
データ同化を実装できるツールを教えてください。
商用とOSSの両方を整理しよう。
| ツール | 種別 | 特徴 |
|---|---|---|
| Ansys Twin Builder | 商用 | ROMベースのデジタルツインにDA機能を統合 |
| MATLAB UKF/EKF | 商用 | System Identification Toolboxでカルマンフィルタ実装 |
| OpenDA | OSS | Java/Fortranベースの汎用DAフレームワーク |
| DAPPER | OSS | PythonのDA実験・ベンチマーク用ライブラリ |
| filterPy | OSS | 軽量なカルマンフィルタ実装 |
| pyDA | OSS | EnKF/3D-VarのPython実装 |
商用CAEソルバーとの連携はどうなっていますか?
AbaqusはPython APIでソルバーをバッチ実行できるので、EnKFのループに組み込みやすい。Ansys Mechanicalも同様にACT拡張やPyMAPDLで制御可能だ。Code_Asterはサロメ-メカプラットフォーム上でPython統合ができるのでDAとの親和性が高い。
選定指針
どう選べばいいですか?
重要なのは、DAフレームワーク単体ではなく、FEMソルバーとのインターフェース部分の開発工数が支配的になることだ。
気象業界のデータ同化ソフトがCAEに来た——DALECとOpenDA
データ同化ソフトウェアは長らく気象・海洋分野固有のものだったが、CAEへの応用を見据えたオープンソースツールが増えてきた。代表格がオランダ・デルフト工科大学発の「OpenDA」。もともとは海洋モデルの同化ライブラリだが、汎用化されてFEM/CFDとのインターフェースも整備されている。商用では仏Dassault SystemèsのSimuliaがデータ同化機能をAbaqus周辺ツールとして展開しており、デジタルツインの文脈で売り込んでいる。一方、物理モデルが確立されていない新素材や複合材料の分野では、DARPA肝入りのDTAP(Digital Twin Applications Platform)のような政府主導のプロジェクトも見逃せない。選定の際は「自分のシミュレーターとのカップリングのしやすさ」が最大の評価軸になる。
データ同化手法の先端研究
最新の研究動向
データ同化の最先端ではどんな研究が行われていますか?
いくつかの重要な方向性がある。
機械学習とデータ同化の融合
ニューラルネットワークでカルマンゲインを直接学習する「Neural Kalman Filter」や、LSTMでモデル誤差を学習して予測を補正する手法が出てきている。従来のDAは線形化やガウス性の仮定を置くが、NNベースの手法はこれらの制約を緩和できる。
高次元状態空間への対応
数百万自由度のFEMモデルに対するDAは計算量が膨大になる。Randomized SVDによるオンライン次元削減、テンソル分解によるアンサンブル表現の圧縮など、スケーラビリティを確保する研究が進んでいる。
デジタルツインとの関係はどうなりますか?
データ同化はデジタルツインの核心技術だ。物理モデルとセンサデータの継続的な同期がデジタルツインの定義そのものと言える。今後はIoTの普及でセンサデータが爆発的に増えるため、高速・大規模なDAの需要はますます高まる。
逆問題としてのパラメータ推定
材料パラメータや境界条件の未知値をDAで同時推定する「結合状態-パラメータ推定」が実用化しつつある。例えば稼働中のタービンブレードのき裂進展パラメータをセンサデータから逐次更新し、余寿命をリアルタイムに予測する研究がある。
この分野の進化のイメージ
CAE技術の進化は「地図の歴史」に似ている。手描きの地図(経験ベースの設計)→印刷地図(従来のCAE)→カーナビ(自動化されたCAE)→スマートフォンのリアルタイムナビ(AI統合CAE)と、「より速く、より正確に、より簡単に」進化している。
データ同化手法のトラブル対応
よくある問題と対策
データ同化を実装してみたけどうまくいかないとき、何を確認すればいいですか?
典型的なトラブルを紹介しよう。
1. フィルタの発散
症状: 推定値が時間とともに観測からどんどん乖離していく。
原因と対策:
- アンサンブルサイズが小さすぎる。最低50、できれば100以上にする
- インフレーション係数の設定。共分散が過小評価されるとフィルタが過度に自信を持ち、観測を無視してしまう。$\rho = 1.01$〜$1.10$程度のインフレーションを試す
- モデルバイアスの存在。系統誤差があるとフィルタは補正しきれない。バイアス項を状態ベクトルに追加する
2. 推定値が非物理的になる
症状: 負のヤング率や非現実的な温度が推定される。
原因と対策:
- パラメータの制約条件が未設定。対数変換やシグモイド変換で物理的に許容される範囲に制限する
- 観測演算子の線形化誤差が大きい。反復的なEnKF(IEnKF)に切り替える
3. 計算コストが現実的でない
症状: アンサンブル全体のFEM実行に何日もかかる。
対策:
- PODベースのROMで各メンバーの計算を高速化する
- ドメイン局所化で状態ベクトルのサイズを削減する
- 並列計算でアンサンブルメンバーを同時実行する
観測誤差の設定を間違えるとどうなりますか?
$\mathbf{R}$ を小さくしすぎると、ノイズの乗った観測を過度に信頼してフィルタが振動する。大きくしすぎると観測情報を活用しきれない。センサのスペックシートから分かる精度情報を基に設定し、双子実験で妥当性を検証するのが王道だ。
4. センサ配置が不適切
症状: 一部の状態変数の推定精度だけが悪い。
対策:
- 観測可能性の解析を行い、センサ情報が全状態変数に影響を与えるか確認する
- D-最適計画やA-最適計画に基づくセンサ配置最適化を実施する
観測データが「嘘をつく」——センサー異常とデータ同化の相性問題
データ同化の実装でよくハマるのが「センサー故障時のモデル破壊」問題だ。カルマンフィルタは観測データを「真実に近い信号」として扱うため、センサーが異常値を出すとモデル全体が汚染される。ある橋梁の構造健全性モニタリングシステムでは、落雷による一瞬のノイズがカルマンフィルタの共分散行列を発散させ、それ以降の推定値が完全に破綻するという事故が起きた。対策としてはイノベーション(観測とモデル予測の差)のサイズでアウトライアを事前に検出し、怪しいデータを同化から除外するゲーティング処理が不可欠だ。χ²検定でイノベーションの統計的妥当性をチェックするのが標準的な手法で、これを実装するかどうかで本番システムの安定性が大きく変わる。
構造解析の収束問題や計算コストに課題を感じていませんか? — Project NovaSolverは、実務者が日々直面するこうした課題の解決を目指す研究開発プロジェクトです。
データ同化手法の実務で感じる課題を教えてください
Project NovaSolverは、CAEエンジニアが日々直面する課題——セットアップの煩雑さ、計算コスト、結果の解釈——の解決を目指しています。あなたの実務経験が、より良いツール開発の原動力になります。
お問い合わせ(準備中)関連トピック
なった
詳しく
報告