デジタルツインとML
理論と物理
概要
デジタルツインって最近よく聞くんですけど、CAEとの関係を教えてください。
デジタルツインとは、実世界の物理システムの仮想コピーをシミュレーションモデルとして構築し、センサデータとの同期を通じてリアルタイムに状態を監視・予測する技術だ。CAEの物理モデルに機械学習を組み合わせることで、高速な予測と適応的な更新を実現する。
普通のCAEシミュレーションと何が違うんですか?
決定的な違いは「生きている」点だ。通常のCAEは設計段階で一度実行して終わりだが、デジタルツインは運用中ずっとセンサデータを取り込んで自分自身を更新し続ける。これによって経年劣化、予想外の荷重、環境変化に対応した予測ができる。
支配方程式
数式ではどう表されるんですか?
状態空間モデルとして定式化される。システムの状態 $\mathbf{x}_k$ は時間発展方程式に従い、観測 $\mathbf{y}_k$ はその部分的な測定値だ。
ここで $f$ は物理モデル(FEM等)、$\mathbf{u}_k$ は入力(荷重等)、$\mathbf{w}_k$ はモデル誤差、$h$ は観測演算子、$\mathbf{v}_k$ は観測ノイズだ。MLは$f$の高速近似(サロゲートモデル)として、あるいはモデル誤差 $\mathbf{w}_k$ の学習に使われる。
MLが入ることで何が嬉しいんですか?
FEMの$f$をそのまま使うとリアルタイム更新に間に合わない。MLで$f$を近似することで、秒単位の予測が可能になる。さらに、物理モデルでは表現しきれない劣化メカニズムや環境依存性をデータから学習できる。
物理インフォームドアプローチ
物理モデルとMLをどう組み合わせるんですか?
3つのパターンがある。
1. ハイブリッド型: 物理モデルの出力をMLで補正する。$\hat{y} = f_{\text{physics}}(x) + f_{\text{ML}}(x, \text{residual})$
2. サロゲート型: 物理モデル全体をMLで置き換える。高速だが外挿性に課題
3. 物理制約埋込型: PINNのように物理法則を損失関数に埋め込んだMLモデルを使う
実用上はハイブリッド型が最も信頼性が高い。物理モデルで大局的な挙動を捉え、MLで残差を修正する構成だ。
デジタルツインの定義論争——「双子」はどこまで「生きている」のか
「デジタルツイン」という言葉、実は定義が人によってバラバラなのをご存知だろうか。NASA的な定義は「実機の状態をリアルタイムで反映する高忠実度シミュレーション」だが、製造業での実態は「3D CADモデルにセンサーデータをひもづけたダッシュボード」にとどまるケースが多い。理論的に本物のデジタルツインを作ろうとすると、物理モデル・データ同化・MLサロゲート・不確実性定量化の4つが全て揃っていないといけない。GEのガスタービンデジタルツインはその中でも先進的で、エンジン1基あたり数千のセンサー信号を300以上のFEMサブモデルとリアルタイム同化している。ただし維持費だけで年間数億円規模かかるとも言われ、「本物のDT」がいかに重いかが分かる。
各項の物理的意味
- 保存量の時間変化項:対象とする物理量の時間的変化率を表す。定常問題では零となる。【イメージ】浴槽にお湯を張るとき、水位が時間と共に上がる——この「時間あたりの変化速度」が時間変化項。バルブを閉じて水位が一定になった状態が「定常」であり、時間変化項はゼロ。
- フラックス項(流束項):物理量の空間的な輸送・拡散を記述する。対流と拡散の2種類に大別される。【イメージ】対流は「川の流れがボートを運ぶ」ように流れに乗って物が運ばれること。拡散は「インクが静止した水中で自然に広がる」ように濃度差で物が移動すること。この2つの輸送メカニズムの競合が多くの物理現象を支配する。
- ソース項(生成・消滅項):物理量の局所的な生成または消滅を表す外力・反応項。【イメージ】部屋の中でヒーターをつけると、その場所に熱エネルギーが「生成」される。化学反応で燃料が消費されると質量が「消滅」する。外部から系に注入される物理量を表す項。
仮定条件と適用限界
- 連続体仮定が成立する空間スケールであること
- 材料・流体の構成則(応力-歪み関係、ニュートン流体則等)が適用範囲内であること
- 境界条件が物理的に妥当かつ数学的に適切に定義されていること
次元解析と単位系
| 変数 | SI単位 | 注意点・換算メモ |
|---|---|---|
| 代表長さ $L$ | m | CADモデルの単位系と一致させること |
| 代表時間 $t$ | s | 過渡解析の時間刻みはCFL条件・物理的時定数を考慮 |
数値解法と実装
実装アーキテクチャ
デジタルツインのシステムはどう構成するんですか?
主要なコンポーネントを整理しよう。
| 層 | コンポーネント | 役割 |
|---|---|---|
| データ収集層 | IoTセンサ、SCADA | 温度、ひずみ、振動等のリアルタイム取得 |
| 通信層 | MQTT, OPC-UA | センサからクラウド/エッジへのデータ転送 |
| モデル層 | FEM + ROM + ML | 物理予測と高速推論 |
| 同化層 | EnKF, パーティクルフィルタ | センサデータによるモデル更新 |
| 可視化層 | 3Dダッシュボード | 状態の可視化とアラート |
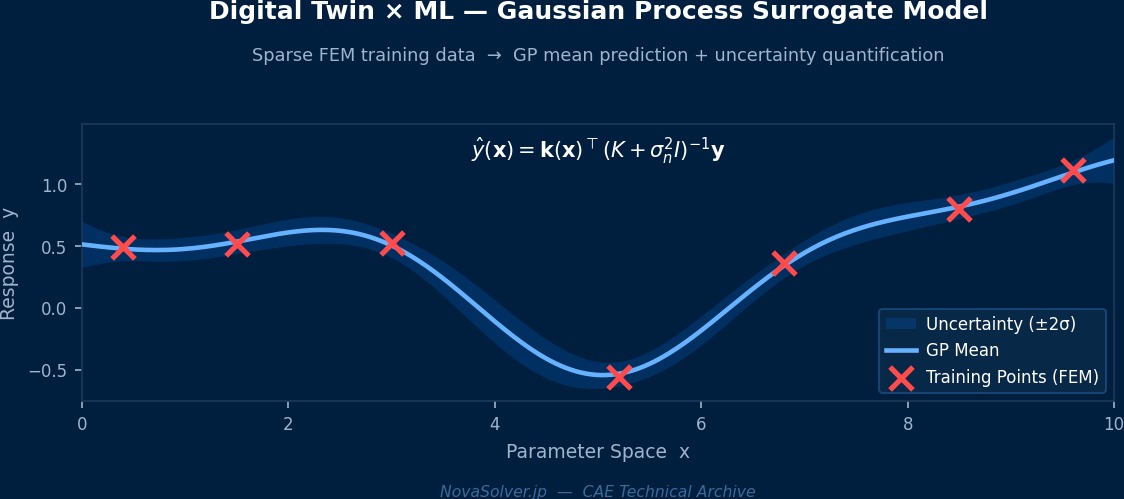
ROMってどうやって作るんですか?
POD(固有直交分解)が標準的だ。フルFEMの解を多数計算してスナップショット行列を構成し、SVDで主要な基底ベクトルを抽出する。元が100万自由度のモデルでも、10〜50個の基底で90%以上のエネルギーを捕捉できることが多い。これにより計算が数万倍高速化する。
MLモデルの学習と更新
MLモデルの学習データはどう作るんですか?
2段階の学習が一般的だ。
オフライン学習: 設計段階でパラメトリックFEM解析を大量に実行し、パラメータ-応答のデータセットを作ってMLモデルを事前学習する。ラテン超方格(LHS)でパラメータ空間を効率的にカバーする。
オンライン学習: 運用開始後、実際のセンサデータを使ってモデルを逐次更新する。転移学習やファインチューニングで少量の実データに適応させる。
オンライン学習ってリアルタイムでやるんですか?
必ずしもリアルタイムではない。多くの場合、日次や週次でバッチ的にモデルを更新する。リアルタイム性が必要なのはデータ同化(状態推定)の部分で、モデル自体のパラメータ更新はもう少し緩いサイクルで回す。
エッジ展開の考慮事項
クラウドじゃなくて現場のエッジで動かしたい場合はどうすればいいですか?
モデルの軽量化が鍵だ。ONNX形式でエクスポートしてONNX Runtimeで推論する、量子化(INT8)で計算を軽くする、TensorRT等でGPU推論を最適化する、といった手法がある。推論に必要な計算量が100MFLOPS程度に収まれば、NVIDIA Jetsonのようなエッジデバイスでもミリ秒単位の応答が可能だ。
サロゲートモデルがデジタルツインを「速く」する——FNO vs POD-ROM
デジタルツインのリアルタイム性を支えるのがサロゲートモデル(代替モデル)だ。フルFEMを毎ステップ走らせるのは計算的に無理なので、軽量な近似モデルで高速化する。古典的手法はPOD(固有直交分解)ベースのROM(低次元モデル)だが、非線形性が強い問題では精度が出ない。2020年代に入って注目を集めているのがFourier Neural Operator(FNO)だ。MIT×Caltech共同研究のFNOは「関数から関数への写像」を学習するアーキテクチャで、ナビエ・ストークス方程式のサロゲートとして従来手法の1000倍速を実現した事例もある。Ansys SimAIにも類似思想が採用されており、数時間かかるCFD解析を数秒で近似するデモが公開されている。
低次要素
計算コストが低く実装が簡単だが、精度は限定的。粗いメッシュでは大きな誤差が生じる可能性がある。
高次要素
同一メッシュでより高い精度を達成。計算コストは増加するが、必要な要素数は少なくなる場合が多い。
ニュートン・ラフソン法
非線形問題の標準的手法。収束半径内で2次収束。$||R|| < \epsilon$ で収束判定。
時間積分
離散化のイメージ
数値解法は「デジタルカメラで写真を撮る」ことに似ている。現実の連続的な風景(連続体)を有限個のピクセル(要素/セル)で表現する。ピクセル数(メッシュ密度)を上げれば画質(精度)は向上するが、ファイルサイズ(計算コスト)も増える。最適なバランスを見つけることが実務の腕の見せどころ。
実践ガイド
プロジェクト立ち上げの手順
デジタルツインのプロジェクトはどこから始めればいいですか?
最初から大規模にやろうとすると失敗する。段階的に進めるのが鉄則だ。
フェーズ1: 価値実証(PoC) — 単一コンポーネント、少数のセンサ、簡易モデルで「予測が実測と合うか」を検証する。期間は3〜6ヶ月
フェーズ2: パイロット運用 — 実運用環境でデータを蓄積し、モデルを段階的に改善する。オンライン学習の仕組みを構築する。期間は6〜12ヶ月
フェーズ3: 本格展開 — 複数コンポーネント、マルチフィジックス対応に拡張する。運用保守体制を確立する
PoCで失敗するパターンってありますか?
最も多いのは「データが足りない」パターンだ。センサの設置場所が不適切だったり、サンプリング周波数が低すぎたり、そもそもデータ品質が悪かったり。PoCの前にセンサ計画をしっかり立てることが重要だ。
ベストプラクティス
成功の秘訣を教えてください。
適用事例
具体的にどんな事例がありますか?
| 業界 | 対象 | 効果 |
|---|---|---|
| 航空 | ジェットエンジンのタービンブレード | 余寿命予測で整備計画を最適化 |
| 風力発電 | 風力タービンのドライブトレイン | 故障予兆検知で突発停止を回避 |
| 橋梁 | 鋼橋の疲労損傷 | ひずみセンサとFEMの同化で損傷箇所を特定 |
| 自動車 | バッテリーパック | 温度分布予測と劣化監視 |
| プラント | 圧力容器 | クリープ寿命のオンライン更新 |
ボーイング787デジタルツイン——複合材機体の「老い」を追跡する
航空機の機体維持管理にデジタルツインが本格活用されている。ボーイングが787に展開しているシステムは、飛行ごとに記録される数万チャンネルのFDR(飛行データ記録装置)データを構造FEMシミュレーションに結びつけ、複合材外板の疲労損傷を機体固有の履歴で追跡する。これにより従来の「全機一律の点検スケジュール」から「その機体の実使用に応じた個別スケジュール」への移行が実現した。実装上の最大の課題は「誰がモデルを更新するか」の体制作りだった。機体設計部門、MRO(整備・修理・オーバーホール)部門、ITシステム部門が縦割りになっており、シミュレーターのバージョン管理とデータパイプラインの整合性維持が技術面以上に組織面での難題だったという。
この解析分野のイメージ
CAE解析の実務は「仮想実験室」——物理的な試作なしに製品の挙動を予測できる。ただし「ゴミを入れればゴミが出る(GIGO: Garbage In, Garbage Out)」という格言通り、入力データの品質が結果の信頼性を決定する。
解析フローのたとえ
解析フローは「科学実験」に似ている。仮説(解析モデル)を立て、実験(計算実行)し、結果を検証し、仮説を修正する——このPDCAサイクルが品質の高い解析を生む。
初心者が陥りやすい落とし穴
最もよくある失敗は「結果の検証を怠る」こと。美しいコンター図が得られても、それが物理的に正しいとは限らない。必ず理論解、実験データ、またはベンチマーク問題との比較を行うこと。
境界条件の考え方
境界条件は「実験の治具」に相当する。治具の設計が不適切であれば実験結果が無意味になるように、CAEでも境界条件が現実を正しく表現しているかが最も重要。
ソフトウェア比較
主要プラットフォーム
デジタルツインの商用ツールにはどんなものがありますか?
CAE系と IoT系の2系統がある。
| プラットフォーム | 提供元 | 特徴 |
|---|---|---|
| Ansys Twin Builder | Ansys | ROM生成からデプロイまで一貫対応 |
| Siemens Simcenter | Siemens | MindSphereとの IoT統合 |
| Dassault 3DEXPERIENCE | Dassault | PLMとの統合、クラウドネイティブ |
| Azure Digital Twins | Microsoft | クラウド基盤、IoT Hub連携 |
| AWS IoT TwinMaker | Amazon | 3D可視化、Grafana連携 |
| NVIDIA Omniverse | NVIDIA | リアルタイム3D、物理シミュレーション連携 |
CAEベンダーとITベンダーのどちらを選ぶべきですか?
物理モデルの精度が重要な場合はCAEベンダー系が有利だ。既存のFEMモデル資産をそのまま活用できる。一方、大量のIoTデータの処理基盤やスケーラビリティが優先ならクラウドベンダー系を選ぶ。理想的には両者を組み合わせる。
コスト構造
デジタルツインの導入コストはどれくらいですか?
大きな費用項目は3つだ。
1. センサ/IoTインフラ: 1システムあたり数百万〜数千万円。センサの種類と数に依存
2. CAEモデル構築とROM化: 数百万〜数千万円。既存モデルの流用度合いに依存
3. プラットフォーム利用料: 年間数十万〜数百万円。クラウド従量課金
最大のコスト要因は実は人件費で、CAEエンジニアとデータサイエンティストの協業体制を構築するのに最も工数がかかる。
Siemens Xcelerator vs Ansys Twin Builder——デジタルツインプラットフォームの競合
デジタルツインプラットフォーム市場は今、SiemensとAnsysが激しく競っている。Siemens XceleratorはNX/TeamcenterとMindSphereクラウドを統合し、製品ライフサイクル管理(PLM)と解析を一体化するエコシステム戦略。Ansys Twin BuilderはFEM/CFD/回路シミュレーターを横断した「システムシミュレーション」が強みで、Pythonスクリプトとの連携がしやすい。一方、MathWorksのSimulinkはコントロールエンジニアの間で根強い人気があり、デジタルツインの制御ループ部分に強い。実際の大手自動車メーカーでは3社のツールを用途別に使い分けている例も珍しくなく、インターオペラビリティ(FMI/FMUフォーマット対応)が選定の重要条件になっている。
ツール選びのたとえ
CAEツールの選定は「道具箱」の構築に似ている。1つの万能ツールですべてをカバーするか、用途ごとに最適な専用ツールを揃えるか——予算、スキル、使用頻度に応じた戦略が必要。
選定で最も重要な3つの問い
- 「何を解くか」:デジタルツインとMLに必要な物理モデル・要素タイプが対応しているか。例えば、流体ではLES対応の有無、構造では接触・大変形の対応能力が差になる。
- 「誰が使うか」:初心者チームならGUIが充実したツール、経験者ならスクリプト駆動の柔軟なツールが適する。自動車のAT車(GUI)とMT車(スクリプト)の違いに似ている。
- 「どこまで拡張するか」:将来の解析規模拡大(HPC対応)、他部門への展開、他ツールとの連携を見据えた選択が長期的なコスト削減につながる。
先端技術
最新研究動向
デジタルツインの研究最前線はどうなっていますか?
3つの大きなトレンドがある。
自律型デジタルツイン
人間の介入なしにモデルが自動的に更新・最適化するシステムの研究が進んでいる。強化学習エージェントがモデルの更新戦略を学習し、「いつ・どの部分を・どの程度更新すべきか」を自動判断する。
マルチフィデリティ融合
異なる精度レベルのモデル(高精度FEM、中精度ROM、低精度経験式)を動的に切り替える手法。計算コストと精度のバランスをリアルタイムに最適化する。急激な状態変化が検知されたら高精度モデルに切り替え、定常状態では軽量モデルで監視する。
デジタルツインの連成
複数のコンポーネントのデジタルツインを連結してシステムレベルのデジタルツインを構築する研究。例えばエンジンのブレード、ディスク、軸受それぞれのデジタルツインを連成させて、エンジン全体の健全性を評価する。
標準化の動きはありますか?
ISO 23247(デジタルツインフレームワーク)が策定され、用語と参照アーキテクチャが定義された。産業界ではDigital Twin Consortium (DTC)がベストプラクティスの共有を推進している。今後はデジタルツインの品質保証や認証の枠組みが整備されていくだろう。
量子コンピューティング×デジタルツイン——次の10年の予告編
デジタルツインの「計算ボトルネック」を根本から解決するかもしれない技術として、量子コンピューティングとの融合研究が始まっている。IBMとボッシュの共同プロジェクトでは、電動モーター電磁界解析の一部を量子変分アルゴリズム(VQE)で解くプロトタイプを開発。現時点では古典スパコンに大きく劣るものの、量子ビット数が増えれば有限要素行列の固有値問題を指数関数的に高速化できる理論的可能性がある。一方でCAEにとって現実的な近未来技術は「量子インスパイア」アルゴリズムだ。Fujitsuのデジタルアニーラは量子的な組合せ最適化をFPGA上で模倣し、自動車部品のトポロジー最適化問題を大幅に高速化する実績を出している。
この分野の進化のイメージ
CAE技術の進化は「地図の歴史」に似ている。手描きの地図(経験ベースの設計)→印刷地図(従来のCAE)→カーナビ(自動化されたCAE)→スマートフォンのリアルタイムナビ(AI統合CAE)と、「より速く、より正確に、より簡単に」進化している。
なぜ先端技術が必要なのか — デジタルツインとMLの場合
従来手法でデジタルツインとMLを解析すると、計算時間・精度・適用範囲に限界がある。例えば、設計パラメータを100通り試したい場合、従来手法では100回の解析が必要だが、サロゲートモデルを使えば数回の解析結果から100通りの予測が可能になる。「全部試す」から「賢く推測する」への転換が先端技術の本質。
トラブルシューティング
よくある問題と対策
デジタルツインの運用で起こりがちなトラブルを教えてください。
主なトラブルを列挙しよう。
1. モデルと実測の乖離が増大する
症状: 運用開始当初は合っていた予測が、時間とともにずれていく。
原因と対策:
- 経年劣化がモデルに反映されていない。劣化パラメータをオンライン推定する仕組みを追加する
- センサのドリフト。定期キャリブレーション、冗長センサによるクロスチェック
- 運転条件が設計時の想定から逸脱。モデルの適用範囲を明示し、範囲外では警告を出す
2. リアルタイム性が確保できない
症状: モデルの応答が遅く、監視に使えない。
対策:
- ROMの基底数を削減する(精度とのトレードオフを確認)
- ML推論をGPUやFPGAで高速化する
- 更新頻度を下げる(毎秒更新が不要なら毎分に変更)
3. データパイプラインの障害
症状: センサデータが途切れた際にモデルが暴走する。
対策:
- 欠損データ時はモデル予測のみで運用する(予測モードへの自動切替)
- データ品質チェックを入れ、異常値をフィルタリングしてからモデルに入力する
- 通信の冗長化(有線+無線のバックアップ)
センサの数を増やせば精度は上がりますか?
必ずしもそうではない。冗長なセンサは情報をほとんど追加しないので、情報理論的にセンサ配置を最適化すべきだ。むしろセンサの質(精度、安定性、応答速度)のほうが量より重要な場合が多い。
4. モデル更新時の安定性
症状: オンライン学習でモデルを更新したら予測が急に不安定になった。
対策:
- 学習率を十分小さくする。破局的忘却(catastrophic forgetting)を防ぐ
- 更新前後で既知のベンチマークケースでの予測を比較し、性能劣化がないことを確認する
- ロールバック機能を実装し、問題があれば前のモデルに戻せるようにする
デジタルツインの「時間遅れ」問題——レイテンシとの格闘
デジタルツインを「リアルタイム」と呼ぶとき、その「リアルタイム」がどの程度かは用途によって全く違う。製造ラインの工作機械制御なら数ミリ秒以内が必要で、橋梁の長期劣化監視なら1時間遅れでも問題ない。よくあるトラブルは「センサーデータの収集→前処理→同化→解析→結果表示」のパイプライン全体のレイテンシを甘く見積もること。特定の自動車工場では、溶接ロボットのリアルタイムFEM更新システムを導入したところ、クラウド通信遅延が予想の3倍かかり制御ループに間に合わなかった。解決にはエッジコンピューティング(工場内サーバー)への移行と、MLサロゲートで重い解析を軽量化する2段構えが必要だった。「クラウド前提設計」は通信コストと遅延を必ず事前検証すること。
デバッグのイメージ
CAEのトラブルシューティングは「探偵の推理」に似ている。エラーメッセージ(証拠)を集め、状況(設定の変更履歴)を整理し、仮説(原因の推定)を立て、検証(設定の変更と再実行)を繰り返す。
「解析が合わない」と思ったら
- まず深呼吸——焦って設定をランダムに変えると、問題がさらに複雑になる
- 最小再現ケースを作る——デジタルツインとMLの問題を最も単純な形で再現する。「引き算のデバッグ」が最も効率的
- 1つだけ変えて再実行——複数の変更を同時に行うと、何が効いたか分からなくなる。科学実験と同じ「対照実験」の原則
- 物理に立ち返る——計算結果が「重力に逆らって物が浮く」ような非物理的な結果なら、入力データの根本的な間違いを疑う
構造解析の収束問題や計算コストに課題を感じていませんか? — Project NovaSolverは、実務者が日々直面するこうした課題の解決を目指す研究開発プロジェクトです。
デジタルツインとMLの実務で感じる課題を教えてください
Project NovaSolverは、CAEエンジニアが日々直面する課題——セットアップの煩雑さ、計算コスト、結果の解釈——の解決を目指しています。あなたの実務経験が、より良いツール開発の原動力になります。
お問い合わせ(準備中)関連トピック
なった
詳しく
報告