CAEデータ異常検知
CAEデータ異常検知の理論基礎
概要
先生、シミュレーション結果に変なデータが混じってるかどうかって、どうやって見つけるんですか?
それがまさにCAEデータ異常検知の領域だね。大量のシミュレーション結果や実測データの中から、正常パターンから逸脱した挙動を自動的に検出する技術だ。オートエンコーダやIsolation Forestといった機械学習アルゴリズムを使って、人の目では見逃しがちな微妙な異常を捕まえる。
例えばどんな「異常」を検出するんですか?
具体例を挙げると、構造解析で局所的に応力が非物理的に跳ね上がっているケース、CFDでの非定常計算中に突然数値が発散しかける兆候、あるいは実験データとシミュレーション結果の乖離が急に大きくなる箇所などだ。センサ故障の検知にも使える。
支配方程式
異常検知を数式で表すとどうなるんですか?
オートエンコーダを使う場合、入力データ $\mathbf{x}$ をエンコーダ $E$ で低次元に圧縮し、デコーダ $D$ で復元する。正常データなら復元誤差が小さいが、異常データでは大きくなる。これを異常スコアとして使う。
つまり「普通のデータならうまく復元できるけど、変なデータは復元できない」ってことですね。
その通り。学習時の再構成誤差の損失関数はこうなる。
Isolation Forestの場合は別のアプローチで、データ空間をランダムに分割していったとき、異常データは少ない分割回数で孤立する性質を利用する。
理論的基盤
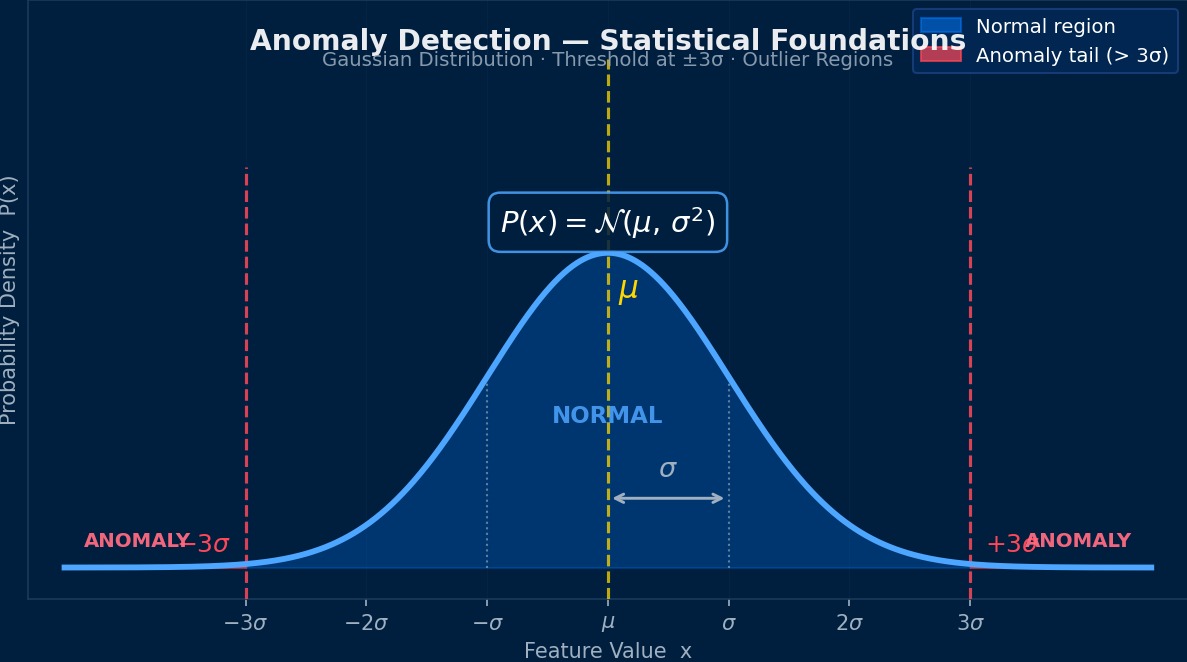
異常検知って、統計的にはどういう位置づけなんですか?
本質的には「正常データの確率分布を学習し、その分布から外れたデータを検出する」問題だ。密度推定の観点からは、正常データの確率密度 $p(\mathbf{x})$ を推定し、閾値 $\tau$ 以下のデータを異常と判定する。ただしCAEデータは高次元かつ非線形な構造を持つため、単純なガウス分布の仮定では不十分で、ニューラルネットワークによる非線形写像が必要になる。
正常の定義が曖昧な場合はどうするんですか?
良い質問だ。教師なし異常検知では正常データだけで学習するが、半教師あり手法では少数の既知異常ラベルを活用する。CAEの文脈では、メッシュ収束済みの高品質シミュレーション結果を「正常」として学習させ、収束不十分やバグ由来の結果を「異常」として検出するのが典型的な使い方だ。
仮定条件と適用限界
どんなデータにでも使えるわけじゃないですよね?
重要な制約がいくつかある。まず、正常データが十分な量あること。正常パターンの多様性をカバーしていないと、未知の正常パターンを異常と誤検知してしまう。また、異常の種類が事前に想定できない場合は教師なし手法に頼るしかないが、検出感度と誤検知率のトレードオフに悩まされる。閾値の設定にはドメイン知識が不可欠だ。
CAE特有の難しさってありますか?
ある。CAEデータは物理量ごとにスケールが全く異なる(応力が10^8 Pa、変位が10^-3 mなど)ので、適切な正規化が必須だ。また、メッシュの違いによって同じ物理現象でもデータ表現が変わるため、メッシュ非依存な特徴量の設計が課題になる。
異常検知の理論的ルーツ——統計学から多様体学習へ
CAEデータの異常検知は、もともと1950年代の品質管理(SPC:統計的プロセス管理)に端を発する地味な分野だ。シューハート管理図の「平均±3σを外れたら異常」という単純ルールが、マハラノビス距離、オートエンコーダ、isolation forestへと進化したのはここ20年の話。理論的に面白いのは「正常状態の多様体を学習する」という考え方。正常データが張る低次元空間から外れた点を異常と見なす発想は、非線形次元削減(UMAP/t-SNEなど)の理論と深くつながっている。流体シミュレーションなら、正常な渦の挙動が張る多様体から逸脱した速度場を「異常」と識別するわけで、物理的直感とも一致しやすい。
CAEデータ異常検知の数値計算手法
主要アルゴリズムの実装
具体的にどんなアルゴリズムを実装すればいいんですか?
代表的な手法を整理しよう。
| 手法 | 原理 | 長所 | 短所 |
|---|---|---|---|
| オートエンコーダ | 再構成誤差 | 高次元データに強い | 閾値設定が困難 |
| Isolation Forest | ランダム分割での孤立度 | 学習が高速、スケーラブル | 局所的な異常に弱い |
| One-Class SVM | 超平面による正常領域の囲い込み | 理論的に堅牢 | 大規模データで計算コスト大 |
| LOF | 局所的な密度比較 | 局所的な異常に強い | 次元の呪いの影響を受ける |
| VAE | 潜在空間の確率分布からの逸脱 | 不確実性の定量化が可能 | 学習が不安定になりやすい |
CAEデータだとどれがおすすめですか?
場のデータ(応力場、温度場など)にはオートエンコーダやVAEが向いている。2D/3Dの空間構造を活かせるConvolutional Autoencoderが特に有効だ。一方、パラメータ空間での異常検知(設計パラメータと応答の関係の逸脱)にはIsolation ForestやLOFが実用的だ。
データ前処理パイプライン
実装するときに最初にやるべきことは何ですか?
データの前処理が成否を分ける。CAEデータ固有のパイプラインはこうだ。
1. スケーリング: 各物理量を個別にMin-Max正規化またはZ-score正規化する。応力と変位を混在させるなら必須
2. 特徴量抽出: 場のデータからスカラー特徴量(最大値、平均、標準偏差、勾配の大きさ)を抽出する方法と、場のデータをそのまま画像として扱う方法がある
3. 欠損値処理: 発散した計算ケースのNaN/Infの除去またはフラグ付け
4. 次元削減: PCAやt-SNEで次元を落としてから異常検知する手もある
HDF5を使うのは何でですか?
大規模CAEデータ(数万ケース、各ケースで数百万節点)をNumPy配列として効率的に読み書きするには、HDF5のチャンクI/Oと圧縮機能が不可欠だ。CSV読み込みに比べて10倍以上速くなることも珍しくない。
実装のポイント
Pythonで書くときの具体的なコツを教えてください。
検証手法
異常検知の性能はどうやって評価するんですか?
精度(Precision)、再現率(Recall)、F1スコア、AUC-ROCが基本指標だ。ただしCAEの文脈では異常データが極めて少ないことが多いので、PR曲線(Precision-Recall曲線)の方がROC曲線より適切な評価になることが多い。また、検出された異常が物理的に意味のあるものかどうかのドメインエキスパートによる確認も欠かせない。
オートエンコーダが「見落とす」異常——再構成誤差の落とし穴
オートエンコーダを使った異常検知の基本的な発想は「正常データで学習したモデルは異常を再構成できない→再構成誤差が大きい=異常」というもの。ところが実務では思わぬ落とし穴がある。例えばある自動車メーカーの衝突シミュレーション品質チェックでは、オートエンコーダが「珍しいが正常な」複雑変形パターンを異常と誤判定してしまった。モデルが正常の多様性を学び切れていなかったのだ。対策としてはβ-VAE(変分オートエンコーダ)で潜在空間を正則化する、もしくはDeep SVDD(Support Vector Data Description)のように正常データの超球を直接学習する手法が有効とされている。
CAEデータ異常検知の実務適用
解析フローの全体像
実務でCAEデータの異常検知をやるとき、どこから手をつければいいですか?
全体の流れはこうだ。
1. 目的の明確化: 何を異常と定義するかを決める。ソルバーの数値エラー検知なのか、設計パラメータの逸脱検知なのかで手法が変わる
2. 正常データベースの構築: メッシュ収束確認済み、V&V済みの信頼できるシミュレーション結果を収集する
3. 特徴量設計: 対象に応じてスカラー特徴量か場データかを選択する
4. モデルの学習と閾値の決定: 交差検証で汎化性能を確認しつつ、誤検知率と見逃し率のバランスを取る
5. 運用と継続的な改善: 新しいデータで定期的にモデルを更新する
正常データベースを作るのが一番大変そうですね。
その通りだ。正常データの品質がモデル全体の信頼性を決める。実務では、経験豊富なCAEエンジニアが確認した「太鼓判付き」の解析結果を正常ラベルとして使う。メッシュ収束確認、力の釣り合い確認、理論解との比較を経た結果だけを採用するのが鉄則だ。
ベストプラクティス
失敗しないためのコツを教えてください。
活用事例
実際にどんな場面で使われてるんですか?
代表的なユースケースはこうだ。
| 活用場面 | 検知対象 | 手法例 |
|---|---|---|
| パラメトリックスタディの品質管理 | 発散・異常収束ケースの自動除外 | Isolation Forest |
| デジタルツイン | センサ故障やモデル劣化の検知 | LSTM-AE |
| 溶接シミュレーション | 非物理的な温度場パターン | Conv-AE |
| 構造最適化 | 非現実的なトポロジー形状 | VAE |
| 疲労解析 | 応力履歴の異常パターン | One-Class SVM |
デジタルツインでの異常検知は面白そうですね。
リアルタイムで稼働中の設備のセンサデータとシミュレーション予測値を比較し、乖離が閾値を超えたらアラートを出す仕組みだ。センサの故障検知と実際の構造劣化の区別ができるのが、物理モデルとの組み合わせの強みだ。
ドキュメント化と報告
結果の報告書にはどんな情報を入れるべきですか?
工場ラインでのCAE異常検知——「誤報」との戦い
実際に製造ラインのCAEデータに異常検知を導入してみると、最初に直面するのは「誤報(false positive)」の嵐だ。ある重工業メーカーでは溶接解析のデータに異常検知モデルを適用したところ、初週で1日あたり200件以上のアラートが発生し、現場の作業員が警告を完全に無視するようになってしまった。教訓は「閾値設定が全て」。ROC曲線でPrecision-Recallのバランスを丁寧に調整し、最終的にF1スコア0.85以上を達成するまで3ヶ月かかったという。また、シフト交代時のセンサー再起動による「正常な突発変化」をモデルが学習するよう、カレンダー情報を特徴量に加えたのも実用上の重要な工夫だった。
CAEデータ異常検知のソフトウェア比較
商用ツールとフレームワーク
異常検知機能を持つCAE関連のツールってあるんですか?
直接「CAEデータ異常検知」を謳うツールはまだ少ないが、周辺のプラットフォームやMLフレームワークを組み合わせて実現する形が主流だ。
| ツール/プラットフォーム | 提供元 | 異常検知との関連 |
|---|---|---|
| Ansys Twin Builder | Ansys | デジタルツインでのリアルタイム異常監視 |
| Altair HyperStudy | Altair | DOE結果のアウトライア検出機能 |
| MATLAB Statistics Toolbox | MathWorks | 統計的異常検知手法の豊富なライブラリ |
| Dataiku / Palantir | 各社 | 汎用データサイエンスPFでの異常検知 |
| scikit-learn | OSS | IsolationForest, LOF等の標準実装 |
| PyOD | OSS | 異常検知専用ライブラリ、30以上の手法 |
PyODって初めて聞きました。
PyODはZhao et al.が開発した異常検知の統合ライブラリで、sklearn互換のAPIで30以上のアルゴリズムが使える。CAE後処理のPythonスクリプトにそのまま組み込めるのが利点だ。BSDライセンスなので商用利用も問題ない。
選定の考え方
どうやって選べばいいですか?
判断軸は3つだ。
1. 既存ワークフローとの統合: すでにAnsysやAbaqusを使っているなら、そのPython APIから直接異常検知パイプラインを呼ぶのが効率的
2. スケーラビリティ: 数万ケースのパラメトリックスタディを対象にするなら、GPUサポートのあるPyTorchベースの実装が必要
3. 説明可能性の要求: 規制産業(航空宇宙、原子力)では異常判定の根拠を説明できる手法(Isolation Forestのパスの可視化など)が求められる
OSSだけで十分対応できそうですね。
現時点ではそうだ。むしろOSSのほうが柔軟にカスタマイズできるし、CAEデータの前処理は結局自前で書く必要がある。商用ツールの価値は、デジタルツインのようなリアルタイム運用基盤を丸ごと提供してくれる点にある。
コスト構造
コスト面ではどうですか?
異常検知自体のソフトウェアコストは低い。大きいのは人件費だ。正常データベースの構築に数人月、モデルの調整と検証に数人月かかることが多い。ただし一度構築すれば、パラメトリックスタディの品質管理工数を大幅に削減できるので、投資対効果は高い。
Ansys SimAIとAzure Anomaly Detector——CAE異常検知ツールの住み分け
CAEデータの異常検知ツールは大きく2系統に分かれる。まずAnsys SimAIのような「CAE専用」ツールは、FEMやCFD特有のメッシュ付き時系列データを直接扱える点が強み。一方、Microsoft Azure Anomaly DetectorやAmazon Lookout for Metricsは汎用的だが、CAEデータのテンソル構造を前処理する手間がかかる。実務での使い分けとしては、シミュレーション品質チェック(収束不良や物理的に非現実的な結果の自動検出)にはAnsys SimAI、センサーデータとの融合分析やダッシュボード統合にはクラウド系サービスが向いている。価格も大きく異なり、クラウド系はAPIコールごとの従量課金なので大量バッチ処理では意外とコストがかさむ点に注意。
CAEデータ異常検知の先端研究
最新研究動向
この分野って今どんな方向に進んでいるんですか?
いくつかの注目すべきトレンドがある。
GNNベースの異常検知
メッシュデータをグラフとして直接扱い、Graph Neural Networkで異常検知を行う手法が出てきている。メッシュの接続構造を保持したまま学習できるので、従来の画像変換ベースの手法よりも情報の損失が少ない。MeshGraphNetsの流れを汲む研究だ。
物理インフォームド異常検知
支配方程式の残差を異常スコアに組み込む手法。例えば応力場が平衡方程式 $\nabla \cdot \boldsymbol{\sigma} + \mathbf{b} = 0$ をどの程度満たしているかを評価し、残差が大きい領域を自動的に異常としてフラグ立てする。PINNの逆問題的な使い方と言える。
物理法則を使うと誤検知が減りそうですね。
その通り。データだけで判断すると「珍しいけど物理的には正しい」結果まで異常扱いしてしまうが、物理制約を入れることで真の異常に絞り込める。
時系列異常検知
非定常シミュレーションの時系列データにLSTM AutoencoderやTransformerベースの異常検知を適用する研究が活発だ。収束過程の異常(通常より遅い収束、振動的な収束)を早期に検出して計算資源の浪費を防ぐことが狙いだ。
この分野の進化のイメージ
CAE技術の進化は「地図の歴史」に似ている。手描きの地図(経験ベースの設計)→印刷地図(従来のCAE)→カーナビ(自動化されたCAE)→スマートフォンのリアルタイムナビ(AI統合CAE)と、「より速く、より正確に、より簡単に」進化している。
CAEデータ異常検知のトラブル対応
よくあるトラブルを整理しよう。
1. 誤検知が多すぎる
症状: 正常なシミュレーション結果まで異常と判定される。
原因と対策:
- 閾値が厳しすぎる。訓練データの99パーセンタイルではなく99.5や99.9に緩める
- 正常データの多様性が不足している。異なる境界条件や材料パラメータの正常ケースを追加する
- 特徴量のスケーリングが不適切。物理量ごとに個別に正規化しているか確認する
2. 既知の異常を見逃す
症状: 明らかにおかしい結果(発散寸前のケースなど)が検知されない。
原因と対策:
- モデルの表現力が不足している。ボトルネック層の次元を増やす、またはより複雑なアーキテクチャに変更する
- 異常の種類が正常データの変動範囲に埋もれている。特徴量設計を見直し、異常に特有の特徴(エネルギーバランスの誤差、力の不釣り合いなど)を追加する
3. 学習が収束しない
症状: オートエンコーダの再構成誤差が下がらない、またはNaNになる。
原因と対策:
- 入力データにNaN/Infが含まれている。前処理で除去すること
- 学習率が高すぎる。1e-4や1e-5に下げる
- 入力データのスケールが大きすぎる。標準化(平均0、分散1)を徹底する
「閾値の設定」が一番悩みそうですね。
実務では閾値は一発で決まらない。まず緩い閾値で運用を始め、誤検知と見逃しの実績データを見ながら段階的に調整するのが現実的だ。ドメインエキスパートとの密な連携が鍵になる。
4. 計算コストが大きすぎる
症状: 大規模データセットでの学習に時間がかかりすぎる。
対策:
- PCAで事前に次元削減してからIsolation Forest等を適用する
- オートエンコーダにはバッチ学習とGPUを活用する
- 増分学習(新しいデータだけで追加学習)が可能な手法を選ぶ
5. メッシュが異なるデータの統合
症状: 異なるメッシュで計算されたケース間で比較ができない。
対策:
- 共通の補間グリッドにリサンプリングしてから特徴量を抽出する
- スカラー特徴量(最大値、平均、RMS等)に集約して比較する
- GNNベースの手法でメッシュ構造ごと学習する
「正常なのに異常と言われる」——コンセプトドリフト問題
CAE異常検知モデルを長期運用していると必ず直面するのが「コンセプトドリフト」問題だ。製造プロセスが改善されたり、材料が変わったりすると、かつて「正常」だったパターンが変化する。あるプレス成形シミュレーションの品質管理システムでは、金型を新しい鋼材仕様に変更した翌日から異常アラートが激増した。モデルが「古い正常」を学んでいたのだ。対処法は大きく2つ:(1)定期的な再学習(リトレーニングパイプラインを自動化)、(2)ADWIN(Adaptive Windowing)やPHT(Page-Hinkley Test)などのオンライン変化検出アルゴリズムを前段に置いてドリフトを自動検知する。どちらもしっかり実装しないと、モデルはじわじわと劣化していく。
構造解析の収束問題や計算コストに課題を感じていませんか? — Project NovaSolverは、実務者が日々直面するこうした課題の解決を目指す研究開発プロジェクトです。
CAEデータ異常検知の実務で感じる課題を教えてください
Project NovaSolverは、CAEエンジニアが日々直面する課題——セットアップの煩雑さ、計算コスト、結果の解釈——の解決を目指しています。あなたの実務経験が、より良いツール開発の原動力になります。
お問い合わせ(準備中)関連トピック
なった
詳しく
報告