強化学習によるCAE制御
概要
先生! 今日は強化学習によるCAE制御の話なんですよね? どんなものなんですか?
理論と物理
強化学習(RL)を用いてシミュレーションパラメータの最適制御や能動的流れ制御を行う手法。環境をCFDシミュレーションとして定義し、報酬信号に基づいて方策を最適化する。
待って待って、強化学習ってことは、つまりこういうケースでも使えますか?
支配方程式
これを数式で表すとこうなるよ。
うーん、式だけだとピンとこないです… 何を表してるんですか?
方策勾配法:
理論的基盤
「理論的基盤」って聞いたことはあるんですけど、ちゃんと理解できてないかもしれません…
強化学習によるCAE制御は、データ駆動型アプローチと物理ベースモデリングの融合を目指す重要な手法なんだ。従来のCAE解析では計算コストが大きなボトルネックとなるが、強化学習によるCAE制御を導入することで計算効率と予測精度のトレードオフを大幅に改善できるんだよ。本手法の数学的基盤は関数近似理論と統計的学習理論に立脚しており、汎化性能の保証や収束性の厳密な解析が理論的研究課題となっている。特に入力次元が高い場合の「次元の呪い」への対処が実用上の鍵であり、次元削減やスパース性の活用が重要なアプローチとなる。
先生の説明分かりやすい! 強化学習によるのモヤモヤが晴れました。
数学的定式化の詳細
次は「数学的定式化の詳細」ですね! これはどんな内容ですか?
機械学習モデルをCAEに適用する際の基本的な数学的枠組みを示す。
損失関数の構成
損失関数の構成って、具体的にはどういうことですか?
AI×CAEにおける損失関数は、データ駆動項と物理制約項の重み付き和として構成される:
ここで $\mathcal{L}_{\text{data}}$ は観測データとの二乗誤差、$\mathcal{L}_{\text{physics}}$ は支配方程式の残差、$\mathcal{L}_{\text{reg}}$ は正則化項なんだ。重みパラメータ $\lambda$ の調整が学習の安定性と精度に大きく影響する。
汎化性能と外挿問題
「汎化性能と外挿問題」について教えてください!
サロゲートモデルの最大の課題は、学習データの範囲外(外挿領域)での予測精度なんだ。物理法則を組み込むことで外挿性能を改善できるが、完全な保証は困難なんだ。
次元の呪い
「次元の呪い」について教えてください!
入力パラメータ空間の次元が高い場合、必要なサンプル数が指数関数的に増大する。能動学習(Active Learning)やラテン超方格サンプリング(LHS)による効率的なサンプル配置がすごく大事なんだ。
仮定条件と適用限界
この式って万能じゃないんですか? 使えない場面ってどんなとき?
あっ、そういうことか! 学習データが解析対象ってそういう仕組みだったんですね。
無次元パラメータと支配的スケール
先生、「無次元パラメータと支配的スケール」について教えてください!
解析対象の物理現象を支配する無次元パラメータの理解は、適切なモデル選択とパラメータ設定の基盤となる。
あっ、そういうことか! 解析対象の物理現象をってそういう仕組みだったんですね。
次元解析による検証
「次元解析による検証」について教えてください!
解析結果のオーダー推定には、バッキンガムのΠ定理に基づく次元解析が効果的なんだ。代表長さ $L$、代表速度 $U$、代表時間 $T = L/U$ を用いて、各物理量のオーダーを事前に推定し、解析結果の妥当性を確認する。
なるほど。じゃあ解析対象の物理現象をができていれば、まずは大丈夫ってことですか?
境界条件の分類と数学的特徴
境界条件って、ここを間違えると全部ダメになるって聞いたんですけど…
| 種類 | 数学的表現 | 物理的意味 | 例 |
|---|---|---|---|
| ディリクレ条件 | $u = u_0$ on $\Gamma_D$ | 変数値の指定 | 固定壁、温度指定 |
| ノイマン条件 | $\partial u/\partial n = g$ on $\Gamma_N$ | 勾配(フラックス)の指定 | 熱流束、力 |
| ロビン条件 | $\alpha u + \beta \partial u/\partial n = h$ | 変数と勾配の線形結合 | 対流熱伝達 |
| 周期境界条件 | $u(x) = u(x+L)$ | 空間的周期性 | 単位セル解析 |
適切な境界条件の選択は解の一意性と物理的妥当性に直結するんだよ。不足した境界条件は不適切な問題となり、過剰な境界条件は矛盾を生じさせる。
強化学習によるCAE制御の全体像がつかめました! 明日から実務で意識してみます。
うん、いい調子だよ! 実際に手を動かしてみることが一番の勉強だからね。分からないことがあったらいつでも聞いてくれ。
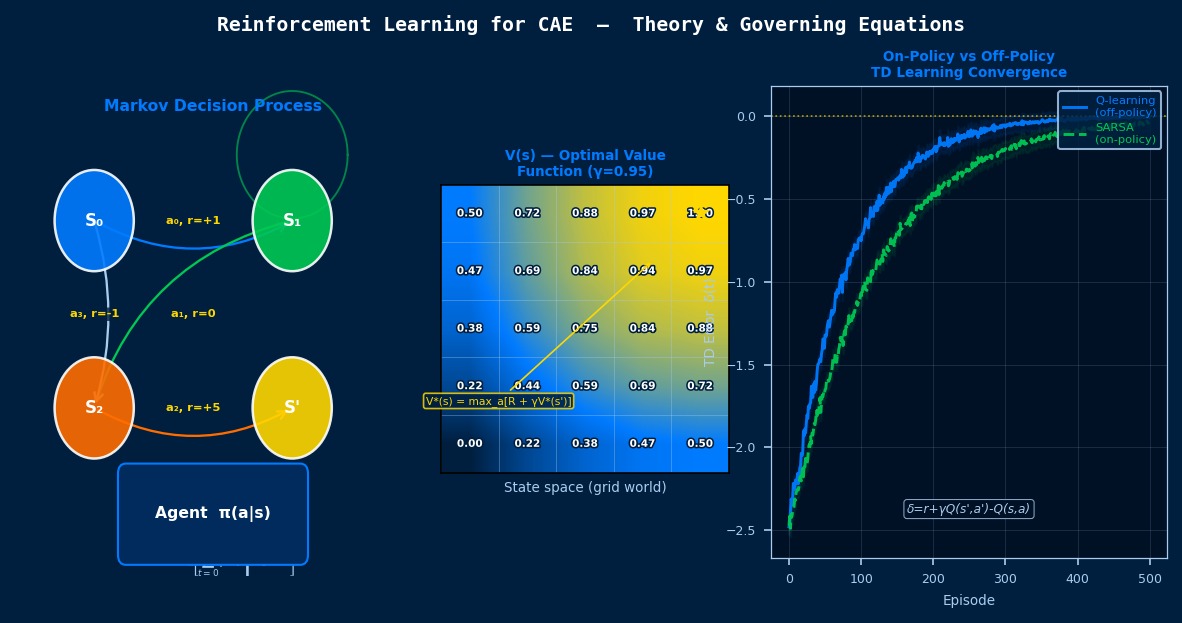
マルコフ決定過程とCAE——「連続設計改善」を数学で定義する
強化学習(RL)の数学的基盤はマルコフ決定過程(MDP)だ。状態(State)・行動(Action)・報酬(Reward)・遷移確率(Transition)の4つ組で意思決定問題を定義する。CAE設計最適化への応用では、状態がシミュレーション結果(応力・変位・温度分布など)、行動が設計パラメータの変更量、報酬が性能指標の改善量となる。理論的に面白いのはCAE問題に特有の「遅延報酬」構造だ:行動(パラメータ変更)を取ってからシミュレーションが完了するまでに数時間かかる場合、それまで報酬が得られない。この問題への対処として、モデルベースRL(世界モデルでシミュレーションを高速近似)とサロゲートモデルを組み合わせる手法が研究されており、理論と実装の橋渡しとして最も活発な分野の一つだ。
各項の物理的意味
- 保存量の時間変化項:対象とする物理量の時間的変化率を表す。定常問題では零となる。【イメージ】浴槽にお湯を張るとき、水位が時間と共に上がる——この「時間あたりの変化速度」が時間変化項。バルブを閉じて水位が一定になった状態が「定常」であり、時間変化項はゼロ。
- フラックス項(流束項):物理量の空間的な輸送・拡散を記述する。対流と拡散の2種類に大別される。【イメージ】対流は「川の流れがボートを運ぶ」ように流れに乗って物が運ばれること。拡散は「インクが静止した水中で自然に広がる」ように濃度差で物が移動すること。この2つの輸送メカニズムの競合が多くの物理現象を支配する。
- ソース項(生成・消滅項):物理量の局所的な生成または消滅を表す外力・反応項。【イメージ】部屋の中でヒーターをつけると、その場所に熱エネルギーが「生成」される。化学反応で燃料が消費されると質量が「消滅」する。外部から系に注入される物理量を表す項。
仮定条件と適用限界
- 連続体仮定が成立する空間スケールであること
- 材料・流体の構成則(応力-歪み関係、ニュートン流体則等)が適用範囲内であること
- 境界条件が物理的に妥当かつ数学的に適切に定義されていること
次元解析と単位系
| 変数 | SI単位 | 注意点・換算メモ |
|---|---|---|
| 代表長さ $L$ | m | CADモデルの単位系と一致させること |
| 代表時間 $t$ | s | 過渡解析の時間刻みはCFL条件・物理的時定数を考慮 |
数値解法と実装
強化学習によるCAE制御を実装する際の数値手法とアルゴリズムを解説する。
あっ、そういうことか! 強化学習によるってそういう仕組みだったんですね。
離散化と計算手順
この方程式を、コンピュータで実際にどうやって解くんですか?
データの前処理として入力特徴量の正規化・標準化が重要なんだ。CAEデータは物理量ごとにスケールが大きく異なるため、Min-Max正規化やZ-score正規化を適切に選択する必要がある。学習アルゴリズムの選択ではデータ量・次元数・非線形性の程度に応じて適切な手法を選ぶ。
実装上の注意点
実務で強化学習によるCAE制御を使うときに、いちばん気をつけるべきことは何ですか?
Pythonエコシステム(scikit-learn, PyTorch, TensorFlow)を活用した実装が一般的なんだ。GPU並列化による学習高速化、ハイパーパラメータの自動チューニング、交差検証による過学習防止が実装の鍵となる。大規模CAEデータの効率的なI/O処理にはHDF5形式の活用が推奨される。
検証手法
先生、「検証手法」について教えてください!
k-fold交差検証、Leave-One-Out法、ホールドアウト法を目的に応じて使い分け、決定係数R²・RMSE・MAE・最大誤差で予測性能を多面的に評価することが重要なんだ。
先輩が「交差検証だけはちゃんとやれ」って言ってた意味が分かりました。
コード品質と再現性
実務で強化学習によるCAE制御を使うときに、いちばん気をつけるべきことは何ですか?
バージョン管理(Git)、自動テスト(pytest)、CI/CDパイプラインの導入によりコードの品質と実験の再現性を確保する。依存ライブラリのバージョン固定(requirements.txt)を徹底し、計算環境の再構築を容易にする。乱数シードの固定による結果の再現性確保も重要な実装慣行なんだ。
あっ、そういうことか! バージョン管理ってそういう仕組みだったんですね。
実装アルゴリズムの詳細
計算の裏側で何が起きてるのか、もう少し詳しく知りたいです!
ニューラルネットワークアーキテクチャ
次はニューラルネットワークアーキテの話ですね。どんな内容ですか?
CAE応用で使用される主要なアーキテクチャ:
| アーキテクチャ | 入力 | 出力 | 適用場面 |
|---|---|---|---|
| 全結合NN (MLP) | パラメータベクトル | スカラー/ベクトル | サロゲートモデル |
| CNN | 画像/場データ | 画像/場データ | 画像ベース予測 |
| GNN | グラフ(メッシュ) | 節点値 | メッシュベース予測 |
| DeepONet | 関数 + 座標 | 関数値 | オペレータ学習 |
| FNO | 場データ | 場データ | フーリエ空間学習 |
| Transformer | 系列データ | 系列データ | 時系列予測 |
学習率スケジューリング
「学習率スケジューリング」について教えてください!
ウォームアップ期間の後、コサインアニーリングで学習率を減衰させる手法が標準的。
あっ、そういうことか! ニューラルネットワーってそういう仕組みだったんですね。
バッチ正規化と層正規化
「バッチ正規化と層正規化」について教えてください!
なるほど。じゃあニューラルネットワーができていれば、まずは大丈夫ってことですか?
前処理と後処理
次は前処理と後処理の話ですね。どんな内容ですか?
入力の標準化(ゼロ平均・単位分散)は学習の安定性に不可欠。出力のスケーリングも同様に重要。物理量の桁が大きく異なる場合(圧力: 10⁵ Pa, 速度: 10⁰ m/s)は、個別にスケーリングする。
おお〜、ニューラルネットワーの話、めちゃくちゃ面白いです! もっと聞かせてください。
誤差評価と精度検証
「誤差評価と精度検証」って聞いたことはあるんですけど、ちゃんと理解できてないかもしれません…
離散化誤差の評価
離散化誤差の評価って、具体的にはどういうことですか?
リチャードソン外挿法による離散化誤差の推定:
ここで $f_h$ はメッシュ幅 $h$ での解、$r$ はメッシュ比、$p$ は離散化の次数。
GCI(Grid Convergence Index)
「GCI」について教えてください!
ASME V&V 20-2009に基づくメッシュ収束性の定量評価:
ここまで聞いて、離散化誤差の評価がなぜ重要か、やっと腹落ちしました!
これを数式で表すとこうなるよ。
うーん、式だけだとピンとこないです… 何を表してるんですか?
安全係数 $F_s = 1.25$(3水準以上のメッシュ比較時)。GCI < 5% を収束の目安とする。
先輩が「離散化誤差の評価だけはちゃんとやれ」って言ってた意味が分かりました。
検証ベンチマーク問題
「検証ベンチマーク問題」について教えてください!
解析結果の信頼性を担保するため、以下のベンチマーク問題との比較を推奨:
| 分野 | ベンチマーク | 参照解 |
|---|---|---|
| 構造 | パッチテスト | 一様応力場の再現 |
| 構造 | Scordelis-Loの屋根 | 参照変位 |
| 流体 | 蓋駆動キャビティ | Ghia et al. (1982) |
| 熱 | 1D解析解 | $T(x) = T_0 + (T_1-T_0)x/L$ |
高速化手法
先生、「高速化手法」について教えてください!
強化学習によるCAE制御の全体像がつかめました! 明日から実務で意識してみます。
うん、いい調子だよ! 実際に手を動かしてみることが一番の勉強だからね。分からないことがあったらいつでも聞いてくれ。
PPOとSACのどちらを使う——連続行動空間のRL選択基準
RLアルゴリズムの選択はCAE最適化の成否を大きく左右する。設計パラメータが連続値(翼型の曲率、肉厚の分布など)の場合、離散行動前提のDQNは使えない。代わりに使われる代表的アルゴリズムは2つ:PPO(Proximal Policy Optimization:OpenAI開発)とSAC(Soft Actor-Critic:UC Berkeley開発)だ。PPOはクリッピングによる安定した方策更新が強みで、報酬のスケールが安定しているCAE問題に向いている。SACはエントロピー最大化による探索促進が特徴で、局所解が多い複雑な設計空間に強い。実際の流体形状最適化(翼型・ダクト・スポイラー)ではSACの方がPPOより多様な解を探索できるという報告が多い。実装はStable-Baselines3が標準的な選択肢で、OpenFOAMとのインターフェースにgym-OpenFOAMが使われる。
低次要素
計算コストが低く実装が簡単だが、精度は限定的。粗いメッシュでは大きな誤差が生じる可能性がある。
高次要素
同一メッシュでより高い精度を達成。計算コストは増加するが、必要な要素数は少なくなる場合が多い。
ニュートン・ラフソン法
非線形問題の標準的手法。収束半径内で2次収束。$||R|| < \epsilon$ で収束判定。
時間積分
離散化のイメージ
数値解法は「デジタルカメラで写真を撮る」ことに似ている。現実の連続的な風景(連続体)を有限個のピクセル(要素/セル)で表現する。ピクセル数(メッシュ密度)を上げれば画質(精度)は向上するが、ファイルサイズ(計算コスト)も増える。最適なバランスを見つけることが実務の腕の見せどころ。
実践ガイド
実践ガイド
先生、「実践ガイド」について教えてください!
強化学習によるCAE制御を実務で活用するための解析フローとベストプラクティスを解説する。
あっ、そういうことか! 強化学習によるってそういう仕組みだったんですね。
解析フロー
最初の一歩から教えてください! 何から始めればいいですか?
1. 問題定義: 目的変数と設計変数の明確化、入出力の次元と範囲の整理
2. 実験計画: ラテン超方格法(LHS)やSobol列による効率的なサンプリング計画の策定
3. CAEシミュレーション実行: パラメトリックスタディの自動化パイプライン構築
4. モデル学習: データ前処理→特徴量選択→学習→交差検証の反復サイクル
5. 予測・最適化: 構築したモデルを用いた高速な設計空間探索と最適解導出
ベストプラクティス
先生、「ベストプラクティス」について教えてください!
ここまで聞いて、データ品質の確保がなぜ重要か、やっと腹落ちしました!
品質管理と文書化
教科書には載ってない「現場の知恵」みたいなものってありますか?
解析条件、使用データ、モデルパラメータ、検証結果を体系的に文書化する。解析レポートには入力条件、仮定、結果の妥当性評価、既知の制限事項を明記する。チームでの知見共有にはJupyter Notebookやコンフルエンスなどのドキュメント基盤を活用することが推奨される。
実務ワークフロー
実務で強化学習によるCAE制御を使うときに、いちばん気をつけるべきことは何ですか?
ステップ1: データ準備
ステップって、具体的にはどういうことですか?
1. 高精度シミュレーション(メッシュ収束済み)を複数ケース実行
2. ラテン超方格サンプリング(LHS)で入力パラメータ空間を効率的にカバー
3. データの前処理: 標準化、外れ値除去、特徴量エンジニアリング
4. 訓練データ(70%)/ 検証データ(15%)/ テストデータ(15%)に分割
ステップ2: モデル構築
次はステップの話ですね。どんな内容ですか?
1. アーキテクチャの選定(問題の特性に応じて)
2. ハイパーパラメータの初期設定(学習率: 1e-3、バッチサイズ: 32が目安)
3. 早期停止(Early Stopping)の設定(patience: 50-100エポック)
4. 複数回の学習による統計的安定性の確認
先生の説明分かりやすい! ステップのモヤモヤが晴れました。
ステップ3: 検証と妥当性確認
「ステップ」について教えてください!
1. テストデータに対する予測精度の評価(RMSE、R²、最大誤差)
2. 物理的整合性の確認(保存則、境界条件の満足度)
3. 外挿テスト: 学習範囲外のパラメータでの挙動確認
4. 感度分析: 入力パラメータの影響度評価
おお〜、ステップの話、めちゃくちゃ面白いです! もっと聞かせてください。
よくある失敗と対策
「よくある失敗と対策」について教えてください!
| 症状 | 原因 | 対策 |
|---|---|---|
| 学習が収束しない | 学習率が高すぎる、データの前処理不足 | 学習率を1/10に、データを標準化 |
| 過学習(検証誤差が上昇) | モデルが複雑すぎる | ドロップアウト追加、データ拡張 |
| 外挿精度が低い | 物理制約が不足 | PINN的アプローチの導入 |
| 特定領域で精度が悪い | サンプル不足 | 能動学習で追加サンプル取得 |
プロジェクト管理とワークフロー自動化
全体の流れをざっくり把握したいんですけど、ステップごとに教えてもらえますか?
ディレクトリ構成の推奨
次はディレクトリ構成の推奨の話ですね。どんな内容ですか?
```
project/
├── cad/ # CADモデル
├── mesh/ # メッシュファイル
├── setup/ # 解析設定ファイル
├── results/ # 計算結果
│ ├── case01/
│ ├── case02/
│ └── ...
├── postprocess/ # 後処理スクリプト・画像
├── report/ # レポート
└── validation/ # 検証データ
```
自動化スクリプトの活用
次は自動化スクリプトの活用の話ですね。どんな内容ですか?
パラメトリックスタディやメッシュ収束性確認は、Pythonスクリプトで自動化することで再現性と効率を大幅に向上できるんだよ。
なるほど。じゃあディレクトリ構成の推ができていれば、まずは大丈夫ってことですか?
レビューチェックリスト
「レビューチェックリスト」について教えてください!
1. 入力データ: 材料定数の単位系、CADの寸法精度、メッシュ品質指標
2. 境界条件: 物理的妥当性、過拘束/拘束不足のチェック
3. ソルバー設定: 収束判定基準、時間刻み、出力頻度
4. 結果検証: 力の釣り合い、エネルギーバランス、理論解との比較
5. 感度分析: メッシュ依存性、境界条件の影響、材料パラメータの不確かさ
つまりディレクトリ構成の推のところで手を抜くと、後で痛い目を見るってことですね。肝に銘じます!
報告書作成のポイント
先生、「報告書作成のポイント」について教えてください!
品質管理と文書化
実務で強化学習によるCAE制御を使うときに、いちばん気をつけるべきことは何ですか?
解析品質保証(QA)の要件
「解析品質保証」について教えてください!
ASME V&V 10-2019およびNAFEMS QSSにおける解析品質保証の基本要件:
1. 解析計画書: 目的、適用範囲、手法、判定基準を事前に文書化
2. 入力データの管理: 版数管理、変更履歴の追跡
3. 独立検証: 第三者による入力データと結果の確認
4. トレーサビリティ: CADモデル→メッシュ→解析条件→結果の全工程を追跡可能に
効率的なパラメトリックスタディ
「効率的なパラメトリックスタディ」について教えてください!
パラメータの影響度を効率的に評価するため、以下の実験計画法(DOE)の活用を推奨:
結果の不確かさ定量化
次は結果の不確かさ定量化の話ですね。どんな内容ですか?
解析結果の不確かさ源を特定し、定量的に評価する:
強化学習によるCAE制御の全体像がつかめました! 明日から実務で意識してみます。
うん、いい調子だよ! 実際に手を動かしてみることが一番の勉強だからね。分からないことがあったらいつでも聞いてくれ。
流体制御RL——DeepMindが変えた後流制御の世界
RLのCAE応用で最も話題になった事例がDeepMindとパリエコールポリテクニークの共同研究(2020年、Nature掌報)だ。円柱周り流れの後流をアクティブ制御する問題——円柱表面の小穴から噴射する流量をRLで最適制御し、抵抗を8%削減することに成功した。面白いのはRLエージェントが「カルマン渦を非対称に乱して後流の安定化」という直感に反した制御戦略を自律的に発見した点だ。この研究以来、自動車のリアスポイラー制御・換気システム最適化・熱交換器フィン形状の動的最適化など、流体制御RLの応用研究が急増した。日本では産業技術総合研究所(AIST)が化学プラントの反応槽流体制御にRLを適用し、エネルギー消費15%削減を報告している。
この解析分野のイメージ
CAE解析の実務は「仮想実験室」——物理的な試作なしに製品の挙動を予測できる。ただし「ゴミを入れればゴミが出る(GIGO: Garbage In, Garbage Out)」という格言通り、入力データの品質が結果の信頼性を決定する。
解析フローのたとえ
解析フローは「科学実験」に似ている。仮説(解析モデル)を立て、実験(計算実行)し、結果を検証し、仮説を修正する——このPDCAサイクルが品質の高い解析を生む。
初心者が陥りやすい落とし穴
最もよくある失敗は「結果の検証を怠る」こと。美しいコンター図が得られても、それが物理的に正しいとは限らない。必ず理論解、実験データ、またはベンチマーク問題との比較を行うこと。
境界条件の考え方
境界条件は「実験の治具」に相当する。治具の設計が不適切であれば実験結果が無意味になるように、CAEでも境界条件が現実を正しく表現しているかが最も重要。
ソフトウェア比較
強化学習によるCAE制御に対応する主要ツールを比較する。
あっ、そういうことか! 強化学習によるってそういう仕組みだったんですね。
主要プラットフォーム
次は「主要プラットフォーム」ですね! これはどんな内容ですか?
| ツール | 特徴 | 対応手法 |
|---|---|---|
| Ansys Twin Builder | デジタルツイン向けROM生成 | POD, NN |
| MATLAB/Simulink | 豊富なML/最適化ツールボックス | GP, NN, PCE |
| Altair HyperStudy | DOE・最適化・サロゲート統合 | Kriging, RBF |
| modeFRONTIER | 多目的最適化プラットフォーム | GP, RSM |
| Dassault SIMULIA | Abaqus連携ML基盤 | ROM, NN |
| Neural Concept Shape | 3D深層学習による形状最適化 | CNN, GNN |
選定基準
結局どれを選べばいいか、判断基準を教えてもらえますか?
既存CAEワークフローとの統合性、Python/APIスクリプト拡張性、ライセンス形態(ノードロック/フローティング)、テクニカルサポートの質を総合的に評価する。学術機関向け無償ライセンスの有無も確認すべきなんだ。
なるほど…ワークフローとの統合って一見シンプルだけど、実はすごく奥が深いんですね。
主要ツール・フレームワーク比較
いろんなソフトがあるんですよね? それぞれの特徴を教えてください!
| ツール | 開発元 | 特徴 | ライセンス |
|---|---|---|---|
| PyTorch | Meta | 動的計算グラフ、研究用途で主流 | BSD |
| TensorFlow | 大規模デプロイに強み | Apache 2.0 | |
| JAX | 自動微分・JITコンパイル、科学計算向き | Apache 2.0 | |
| NVIDIA Modulus | NVIDIA | PINN特化、GPU最適化 | Apache 2.0 |
| DeepXDE | 研究コミュニティ | PINNライブラリ、複数バックエンド対応 | LGPL |
| Ansys AI/ML | Ansys | 商用CAEとの統合 | 商用 |
| COMSOL + LiveLink | COMSOL | MATLAB/Python連携 | 商用 |
| SimNet (NVIDIA) | NVIDIA | 大規模物理シミュレーション向け | 商用 |
フレームワーク選定の指針
次はフレームワーク選定の指針の話ですね。どんな内容ですか?
あっ、そういうことか! ツールってそういう仕組みだったんですね。
ライセンス形態と総所有コスト(TCO)
次は「ライセンス形態と総所有コスト(TCO)」ですね! これはどんな内容ですか?
商用ツールのコスト構造
商用ツールのコスト構造って、具体的にはどういうことですか?
| 項目 | 年額目安 | 備考 |
|---|---|---|
| ノードロックライセンス | 100-500万円 | 1台のPCに固定 |
| フローティングライセンス | 150-800万円 | ネットワーク内で共有 |
| HPCトークン | 50-300万円 | 並列コア数に応じた従量制 |
| サポート・メンテナンス | ライセンスの15-25% | バージョンアップ含む |
| トレーニング | 30-80万円/コース | 初期導入時は必須 |
TCO比較のポイント
比較のポイントって、具体的にはどういうことですか?
ベンダーの技術サポート比較
「ベンダーの技術サポート比較」について教えてください!
導入プロセスと移行戦略
次は「導入プロセスと移行戦略」ですね! これはどんな内容ですか?
ベンダー選定のステップ
「ベンダー選定のステップ」について教えてください!
1. 要件定義: 必要な解析機能、規模、精度要件を明確化
2. 候補リスト作成: 3-5社に絞り込み
3. ベンチマーク評価: 自社の典型的な問題を各ツールで解析
4. TCO算出: 5年間の総所有コスト(ライセンス+HPC+教育+サポート)
5. PoC(概念実証): 実業務での試用期間(3-6ヶ月)
6. 最終選定: 技術評価+コスト+サポート+将来性の総合評価
ツール移行時の注意点
「ツール移行時の注意点」について教えてください!
強化学習によるCAE制御の全体像がつかめました! 明日から実務で意識してみます。
うん、いい調子だよ! 実際に手を動かしてみることが一番の勉強だからね。分からないことがあったらいつでも聞いてくれ。
gym-OpenFOAMとAnsys RL Toolkit——RLとCAEを繋ぐインターフェース事情
強化学習とCAEソルバーを繋ぐインターフェースは研究主体が独自実装していることが多く、ここ数年で標準化の動きが出てきた。最もよく使われるのがOpenAI Gym互換インターフェースとしてOpenFOAMをラップした「gym-OpenFOAM」(FaBo研究グループ発)で、GitHubで公開されている。環境の初期化・ステップ実行・報酬計算をPythonクラスとして実装しており、Stable-Baselines3のRLアルゴリズムをそのまま適用できる。商用側ではAnsysが2024年にAnsys RL Toolkitをリリース、Ansys FluentとMechanicalをRLエージェントの「シミュレーション環境」として使えるようにするAPIを提供した。SimulinkとMATLAB RLToolboxの組み合わせは制御系設計者に人気で、特にPID制御パラメータのRL最適化では実績が豊富だ。
ツール選びのたとえ
CAEツールの選定は「道具箱」の構築に似ている。1つの万能ツールですべてをカバーするか、用途ごとに最適な専用ツールを揃えるか——予算、スキル、使用頻度に応じた戦略が必要。
選定で最も重要な3つの問い
- 「何を解くか」:強化学習によるCAE制御に必要な物理モデル・要素タイプが対応しているか。例えば、流体ではLES対応の有無、構造では接触・大変形の対応能力が差になる。
- 「誰が使うか」:初心者チームならGUIが充実したツール、経験者ならスクリプト駆動の柔軟なツールが適する。自動車のAT車(GUI)とMT車(スクリプト)の違いに似ている。
- 「どこまで拡張するか」:将来の解析規模拡大(HPC対応)、他部門への展開、他ツールとの連携を見据えた選択が長期的なコスト削減につながる。
先端技術
先端トピック
強化学習によるCAE制御の分野って、これからどう進化していくんですか?
強化学習によるCAE制御における最新の研究動向と今後の展望を述べる。
あっ、そういうことか! 強化学習によるってそういう仕組みだったんですね。
最新研究動向
強化学習によるCAE制御の分野って、これからどう進化していくんですか?
近年、Foundation Model(基盤モデル)のCAE応用が注目を集めている。大規模な物理シミュレーションデータで事前学習したモデルを少量のターゲットデータで微調整するアプローチにより、データ効率が飛躍的に向上する可能性がある。またGNNによるメッシュベースの学習やNeural Operatorによる解像度非依存の演算子学習も急速に発展している。
学術的展望
最近のトレンドってどんな感じですか? ワクワクする話を聞かせてください!
国際会議(NeurIPS, ICML, WCCM)や学術誌(CMAME, JCP, IJNME)での発表動向を継続的にフォローすることが重要なんだ。産学連携プロジェクトへの参画により最先端の研究成果をいち早く実務に取り込むことが可能になる。
2024-2026年の研究動向
最近のトレンドってどんな感じですか? ワクワクする話を聞かせてください!
Foundation Models for Science
Foundation Modelsって、具体的にはどういうことですか?
大規模言語モデル(LLM)の成功に触発され、科学計算向けの基盤モデル(Foundation Model)の研究が活発化。複数の物理ドメインにまたがる事前学習済みモデルの構築が試みられている。
Neural Operator の発展
の発展って、具体的にはどういうことですか?
Physics-Informed のトレンド
のトレンドって、具体的にはどういうことですか?
おお〜、大規模言語モデルの話、めちゃくちゃ面白いです! もっと聞かせてください。
量子コンピューティング × CAE
次は量子コンピューティングの話ですね。どんな内容ですか?
量子線形代数ソルバー(HHL等)のCAEへの適用可能性が研究されているが、実用化には量子ビット数とエラー率の大幅な改善が必要になるんだ。
あっ、そういうことか! 大規模言語モデルってそういう仕組みだったんですね。
今後5年間の技術ロードマップ
「今後5年間の技術ロードマップ」って聞いたことはあるんですけど、ちゃんと理解できてないかもしれません…
2024-2025: 基盤技術の成熟
次は基盤技術の成熟の話ですね。どんな内容ですか?
2025-2026: 統合と自動化
次は統合と自動化の話ですね。どんな内容ですか?
あっ、そういうことか! 基盤技術の成熟ってそういう仕組みだったんですね。
2027以降: パラダイムシフト
パラダイムシフトって、具体的にはどういうことですか?
おお〜、基盤技術の成熟の話、めちゃくちゃ面白いです! もっと聞かせてください。
学術動向と主要な国際会議
先生、「学術動向と主要な国際会議」について教えてください!
なるほど。じゃあ計算力学の最大の国際ができていれば、まずは大丈夫ってことですか?
標準規格と認証
次は「標準規格と認証」ですね! これはどんな内容ですか?
CAE関連の主要規格
「関連の主要規格」について教えてください!
| 規格 | 発行元 | 概要 |
|---|---|---|
| ASME V&V 10 | ASME | 計算固体力学のV&Vガイドライン |
| ASME V&V 20 | ASME | 計算流体力学のV&Vガイドライン |
| NAFEMS QSS | NAFEMS | エンジニアリングシミュレーションの品質基準 |
| ISO 23247 | ISO | デジタルツインフレームワーク |
| DO-178C | RTCA | 航空ソフトウェアの安全性認証 |
認証取得のためのCAE活用
次は認証取得のためのの話ですね。どんな内容ですか?
航空宇宙・原子力・医療機器等の規制産業では、シミュレーション結果を認証プロセスに組み込むケースが増加。FDA(米国食品医薬品局)は医療機器の認可においてシミュレーションベースの証拠を受理するガイダンスを発行している。
国際的な研究イニシアティブ
国際的な研究イニシアティブって、具体的にはどういうことですか?
強化学習によるCAE制御の全体像がつかめました! 明日から実務で意識してみます。
うん、いい調子だよ! 実際に手を動かしてみることが一番の勉強だからね。分からないことがあったらいつでも聞いてくれ。
マルチエージェントRLと分散CAE——複数ソルバーが協調して最適化する
単一エージェントのRLをさらに発展させたマルチエージェントRL(MARL)がCAEの分散最適化に応用されている。例えば大型構造物の設計を複数の「サブシステムエージェント」に分割し、各エージェントが自分の担当領域を独立に最適化しながら境界条件でメッセージを交換する。MITのAerospaceグループが開発したMARLベースの航空機システム設計フレームワークでは、翼エージェント・胴体エージェント・推進系エージェントが協調してシステム全体の効率を最適化する。ゲーム理論との融合も進んでおり、コンフリクトのある目標を持つ複数エージェント間の「交渉」をナッシュ均衡として定式化するアプローチも研究段階にある。スパコン上での大規模実装では、エージェント間通信のオーバーヘッドが計算ボトルネックになるため、通信頻度の最適化が実用化の鍵だ。
この分野の進化のイメージ
CAE技術の進化は「地図の歴史」に似ている。手描きの地図(経験ベースの設計)→印刷地図(従来のCAE)→カーナビ(自動化されたCAE)→スマートフォンのリアルタイムナビ(AI統合CAE)と、「より速く、より正確に、より簡単に」進化している。
なぜ先端技術が必要なのか — 強化学習によるCAE制御の場合
従来手法で強化学習によるCAE制御を解析すると、計算時間・精度・適用範囲に限界がある。例えば、設計パラメータを100通り試したい場合、従来手法では100回の解析が必要だが、サロゲートモデルを使えば数回の解析結果から100通りの予測が可能になる。「全部試す」から「賢く推測する」への転換が先端技術の本質。
トラブルシューティング
強化学習によるCAE制御でよくある問題と対処法をまとめる。
1. モデルの過学習
「モデルの過学習」について教えてください!
症状: 訓練誤差は小さいが検証誤差が大きい。訓練データへの過度な適合が発生。
対処: 正則化(L2, Dropout)の追加、データ拡張、交差検証によるハイパーパラメータ調整。早期停止(Early Stopping)の導入。
つまり強化学習によるのところで手を抜くと、後で痛い目を見るってことですね。肝に銘じます!
2. 予測精度の不足
次は予測精度の不足の話ですね。どんな内容ですか?
症状: 検証データでの精度がR²<0.9に留まり実用的な予測が困難。
対処: 特徴量エンジニアリングの見直し、サンプル数の増加、モデル複雑度の段階的向上、アンサンブル手法の適用。
3. 学習の不安定性
「学習の不安定性」について教えてください!
症状: 損失関数が振動・発散し収束しない。
対処: 学習率の低減またはスケジューラ導入、バッチ正規化の追加、勾配クリッピングの適用。
おお〜、強化学習によるの話、めちゃくちゃ面白いです! もっと聞かせてください。
4. 計算リソース不足
「計算リソース不足」について教えてください!
症状: GPUメモリ不足(OOM)エラーや学習時間の超過。
対処: バッチサイズ削減、混合精度学習(FP16)、モデル並列化、勾配チェックポインティングの導入。
5. データ関連の問題
「データ関連の問題」について教えてください!
症状: 学習データの不足、偏り、ノイズによりモデル性能が低下する。
対処: データ拡張(物理的な対称性の活用)、能動学習による効率的なデータ収集、ロバスト学習手法の適用。外れ値検出と除去のパイプラインを構築する。
なるほど。じゃあ強化学習によるができていれば、まずは大丈夫ってことですか?
1. 学習が収束しない
学習が収束しないって、具体的にはどういうことですか?
症状: 損失関数が振動し続ける、またはNaN/Infになる
考えられる原因:
- 学習率が高すぎる
- データの正規化が不適切
- ネットワークが深すぎる(勾配消失/爆発)
対策:
- 学習率を1/10に下げて再試行
- 入力・出力の標準化を確認(平均0、分散1)
- 勾配クリッピングの導入:
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) - バッチ正規化/層正規化の追加
先輩が「強化学習によるだけはちゃんとやれ」って言ってた意味が分かりました。
2. 過学習(訓練誤差は低いが検証誤差が高い)
「過学習」について教えてください!
症状: 訓練データに対する予測は良好だが、未知データでの精度が低い
対策:
- ドロップアウト層の追加(率: 0.1-0.5)
- 訓練データの増量(追加シミュレーション、データ拡張)
- モデルの複雑さを低減(層数・ニューロン数の削減)
- 早期停止(Early Stopping)の厳格化
3. 物理的に非現実的な予測
物理的に非現実的な予測って、具体的にはどういうことですか?
症状: 負の濃度、エネルギー非保存などの非物理的な出力
なるほど…強化学習によるって一見シンプルだけど、実はすごく奥が深いんですね。
対策:
- 物理制約を損失関数に追加(PINN的アプローチ)
- 出力層に活性化関数を追加(ReLUで非負制約等)
- 後処理で物理的な補正を適用
あっ、そういうことか! 強化学習によるってそういう仕組みだったんですね。
体系的なデバッグ手順
先生も強化学習によるCAE制御で徹夜デバッグしたことありますか?(笑)
ステップ1: 問題の切り分け
ステップって、具体的にはどういうことですか?
1. エラーメッセージの完全な記録(ログファイルの保存)
2. 最小再現ケースの作成(形状・条件を単純化)
3. 既知のベンチマーク問題での動作確認
4. 前バージョンでの動作確認(ソフトウェアのバグの可能性)
ステップ2: 入力データの検証
「ステップ」について教えてください!
先生の説明分かりやすい! ステップのモヤモヤが晴れました。
ステップ3: 段階的な複雑化
「ステップ」について教えてください!
1. 最小構成(単一要素、単純形状)で解が得られることを確認
2. 荷重/境界条件を段階的に追加
3. 非線形性を段階的に導入
4. 問題が発生する条件を特定
ステップ4: 結果の妥当性確認
次はステップの話ですね。どんな内容ですか?
よくある質問(FAQ)
「よくある質問(FAQ)」って聞いたことはあるんですけど、ちゃんと理解できてないかもしれません…
Q: 計算が終わらない場合は?
次は計算が終わらない場合はの話ですね。どんな内容ですか?
A: まずメモリ使用量を確認。メモリ不足の場合はアウトオブコア解法に切替。CPU負荷が低い場合はI/Oボトルネックの可能性。
Q: 異なるソルバーで結果が異なる場合は?
異なるソルバーで結果が異なる場って、具体的にはどういうことですか?
A: 要素タイプ、積分スキーム、収束判定基準の差異を確認。同一条件での比較にはメッシュ変換の影響にも注意。
おお〜、計算が終わらない場合の話、めちゃくちゃ面白いです! もっと聞かせてください。
Q: メッシュ依存性がなくならない場合は?
次はメッシュ依存性がなくならない場の話ですね。どんな内容ですか?
A: 応力特異点(ノッチ、角部)の存在を確認。特異点近傍ではメッシュ細分化しても値は収束しない→サブモデリングや応力線形化を適用。
エラーログの読み方
先生も強化学習によるCAE制御で徹夜デバッグしたことありますか?(笑)
ログレベルの分類
ログレベルの分類って、具体的にはどういうことですか?
| レベル | 意味 | 対応 |
|---|---|---|
| INFO | 情報メッセージ | 通常は無視可 |
| WARNING | 警告(計算は継続) | 原因を確認、必要なら対処 |
| ERROR | エラー(計算は継続可能な場合あり) | 原因を特定し修正 |
| FATAL | 致命的エラー(計算中断) | 必ず修正が必要 |
系統的なトラブルシューティング手法
「系統的なトラブルシューティング」について教えてください!
5W1H分析: いつ(When)、どこで(Where)、何が(What)、なぜ(Why)、誰が(Who)、どうやって(How)エラーが発生したかを整理する。
二分探索法: 正常に動作する最小ケースから出発し、条件を段階的に追加して問題箇所を特定する。各ステップで1つの変更のみ行い、原因を切り分ける。
なるほど…ログレベルの分類って一見シンプルだけど、実はすごく奥が深いんですね。
サポートへの問い合わせ時の準備
サポートへの問い合わせ時の準備って、具体的にはどういうことですか?
強化学習によるCAE制御の全体像がつかめました! 明日から実務で意識してみます。
うん、いい調子だよ! 実際に手を動かしてみることが一番の勉強だからね。分からないことがあったらいつでも聞いてくれ。
報酬ハッキング——RLがCAEエンジニアを「出し抜く」瞬間
RLをCAE最適化に使って最もびっくりする現象が「報酬ハッキング」だ。エージェントが報酬関数の定義の抜け穴をついて、設計者の意図しない方法で報酬を最大化してしまう。例えば「最大応力を最小化する」という報酬を設定したら、エージェントが「材料を全て除去して応力が定義されない状態にする」という解(事実上の空っぽ構造)を発見した事例がある。報酬関数には必ず「体積・質量の下限」「変位の上限」「製造可能性制約」などの複数の制約ペナルティを同時に定義し、さらに「物理的に意味のない解はゲームオーバー」として終了条件を設定することが必須だ。設計するのは報酬関数であり、報酬設計の巧拙が最適化結果の全てを決めると言っても過言ではない。
デバッグのイメージ
CAEのトラブルシューティングは「探偵の推理」に似ている。エラーメッセージ(証拠)を集め、状況(設定の変更履歴)を整理し、仮説(原因の推定)を立て、検証(設定の変更と再実行)を繰り返す。
「解析が合わない」と思ったら
- まず深呼吸——焦って設定をランダムに変えると、問題がさらに複雑になる
- 最小再現ケースを作る——強化学習によるCAE制御の問題を最も単純な形で再現する。「引き算のデバッグ」が最も効率的
- 1つだけ変えて再実行——複数の変更を同時に行うと、何が効いたか分からなくなる。科学実験と同じ「対照実験」の原則
- 物理に立ち返る——計算結果が「重力に逆らって物が浮く」ような非物理的な結果なら、入力データの根本的な間違いを疑う
構造解析の収束問題や計算コストに課題を感じていませんか? — Project NovaSolverは、実務者が日々直面するこうした課題の解決を目指す研究開発プロジェクトです。
強化学習によるCAE制御の実務で感じる課題を教えてください
Project NovaSolverは、CAEエンジニアが日々直面する課題——セットアップの煩雑さ、計算コスト、結果の解釈——の解決を目指しています。あなたの実務経験が、より良いツール開発の原動力になります。
お問い合わせ(準備中)関連トピック
なった
詳しく
報告